 |
To examine the benefits of cache sharing under finite cache sizes, we simulate the following schemes using the traces listed in the previous section:
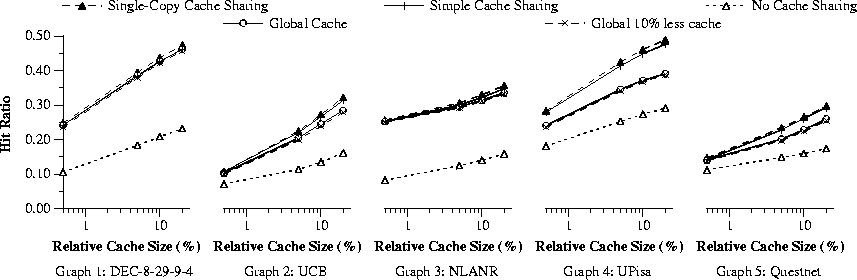
Figure 1 shows the hit ratios under the different schemes considered when the cache size is set to 0.5%, 5%, 10%, and 20% of the size of the ``infinite cache size'' (the minimum cache size needed to completely avoid replacements) for each trace. The results on byte hit ratios are very similar, and we omit them due to space constraints.
Looking at Figure 1, we see that, first, all cache sharing schemes significantly improve the hit ratio over no cache sharing. The results amply confirm the benefit of cache sharing even with fairly small caches.
Second, the hit ratio under single-copy cache sharing and simple cache sharing are generally the same or even higher than the hit ratio under global cache. We believe the reason is that global LRU sometimes performs less well than group-wise LRU. In particular, in the global cache setting a burst of rapid successive requests from one user might disturb the working set of many users. In single-copy or simple cache sharing, each cache is dedicated to a particular user group, and traffic from each group competes for a separate cache space. Hence, the disruption is contained within a particular group.
Third, when comparing single-copy cache sharing with simple cache sharing, we see that the waste of space has only a minor effect. The reason is that a somewhat smaller effective cache does not make a significant difference in the hit ratio. To demonstrate this, we also run the simulation with a global cache 10% smaller than the original. As can be seen from Figure 1, the difference is very small.
Thus, despite its simplicity, the ICP-style simple cache sharing reaps most of the benefits of more elaborate cooperative caching. Simple cache-sharing does not perform any load balancing by moving content from busy caches to less busy ones, and does not conserve space by keeping only one copy of each document. However, if the resource planning for each proxy is done properly, there is no need to perform load-balancing and to incur the overhead of more tightly coordinating schemes.
Finally, note that the results are obtained under the LRU replacement algorithm as explained in Section 2. Different replacement algorithms [8] may give different results. Also, separate simulations have confirmed that in case of severe load imbalance, the global cache will have a better cache hit ratio, and therefore it is important to allocate cache size of each proxy to be proportional to its user population size and anticipated use.