|
|
|
|
|
Homework 2 // Due at Lecture Friday, February 18, 2011Perform this assignment on malbec.cs.wisc.edu, a 64-thread Sun UltraSparc-T2, where we have activated a CS account for you. (Unless you already had an account, you should only use this machine only for CS757 homework assignments or your course project. Unless you have a longer connection for CS, this account and its storage will be removed after the end of the semester.) If you wish to learn more about malbec, run /usr/platform/sun4v/sbin/prtdiag -v on malbec. Malbec is a chip multiprocessor, with 8 8-way multi-threaded cores. Each core has its own L1 cache and executes the threads in approximate round-robin order. The L2 cache is shared by all 8 cores (and 64 threads). The architecture manual and this tuning document describes additional details of this machine. You should do this assignment alone. No late assignments. PurposeThe purpose of this assignment is to give you experience writing a shared memory program with pthreads to build your understanding of shared memory programming, in general, and pthreads, in particular. Programming Environment: PthreadsThe methods of communication and synchronization are two characteristics that define a parallel programming model. In a shared-memory model, all threads access a single address space (hence the name "shared memory"). Thus, communication occurs implicitly, because whenever one thread writes to an address, the update is immediately visible to all others. On the other hand, this introduces the need for explicit synchronization to avoid races among multiple processors to access data at the same address. Different systems support threads in a variety of ways. For this assignment, you will use Posix Threads, or pthreads for short. One advantage of this particular implementation is its portability to many different systems. Do man pthreads from malbec to see a summary of pthreads functions. You can find details for any listed function by doing man function_name. Note that the man page also includes information about Solaris threads. For this assignment, you should use Posix threads, not Solaris threads. All threaded programs begin with a single thread. When you reach a section you wish to do in parallel, you will "fork" one or more threads to share the work, telling each thread in which function to begin execution. Keep in mind that the original, "main" thread continues to execute the code following the fork. Thus, the thread model also provides "join" functionality, which lets you tell the main thread to first wait for a child to complete, and then merge with it. It is likely that you will have many threads execute the same routine, and that you will want each thread to have its own private set of local variables. With pthreads, this occurs automatically. Only global variables are truly shared. When you have multiple threads working on the same data, you may require synchronization for correctness. Pthreads directly supports two techniques: mutual exclusion (locks) and condition variables. A third technique you may find useful is barriers. A barrier makes all threads wait for each other to arrive at a certain point in the code before any of them can continue. While pthreads offers no direct barrier support, you should be able to build a barrier of your own out of the mutual exclusion primitive. A final issue with threads is how they are mapped to processors. Obviously, we can have more threads than processors, but someone must then time multiplex the threads onto the processors. Since this is probably more complexity than you want to deal with, we recommend that you directly bind each thread to a particular processor. More precisely, on Solaris we actually bind threads to light-weight processes (LWP's), but all you really need to know is that by binding threads, you transfer responsibility for contention management of threads on processors to the operating system. Note that all source files that call the pthread API must include the pthread.h header file. Malbec has both the Sun cc/c++ compilers and the GNU gcc/g++ compilers. You may use whichever you choose. When compiling with cc/c++, be sure to specify the -mt compile flag and the -lpthread link flag (note that it's ok to pass both flags during compilation). When using gcc or g++, you will need to use the -lpthread link flag. For more information:
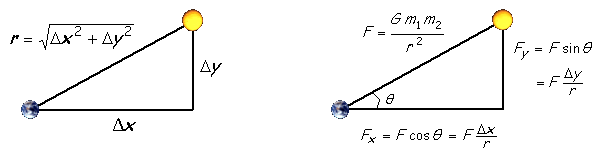
Programming Task: N-Body SimulationAn n-body simulation calculates the gravitational effects of the masses of n bodies on each others' positions and velocities. The final values are generated by incrementally updating the bodies over many small time-steps. This involves calculating the pairwise force exerted on each particle by all other particles, an O(n2) operation. For simplicity, we will model the bodies in a two-dimensional space. The physics. We review the equations governing the motion of the particles according to Newton's laws of motion and gravitation. Don't worry if your physics is a bit rusty; all of the necessary formulas are included below. We already know each particle's position (rx, ry) and velocity (vx, vy). To model the dynamics of the system, we must determine the net force exerted on each particle.
The numerics. We use the leapfrog finite difference approximation scheme to numerically integrate the above equations: this is the basis for most astrophysical simulations of gravitational systems. In the leapfrog scheme, we discretize time, and update the time variable t in increments of the time quantum Δt. We maintain the position and velocity of each particle, but they are half a time step out of phase (which explains the name leapfrog). The steps below illustrate how to evolve the positions and velocities of the particles. For each particle:
As you would expect, the simulation is more accurate when Δt is very small, but this comes at the price of more computation. Problem 1: Write Sequential N-BodyWrite a single-threaded solution to the n-body problem described above. Your program should take as input the number of particles, the length of the time-step Δt, and the number of these time-steps to execute. Your final version should randomly generate the mass, x and y Cartesian coordinates, and x and y velocity components for each particle, then simulate for the specified number of time-steps. For the randomly generated values, you may use any range that you like. However, if you have very large masses which happen to be initialized to positions that are very close to each other, you may encounter overflow. Since the focus of this assignment is parallel programming and scalability, you will not be graded on elegantly handling or avoiding such situations. You are required to make an argument that your n-body implementation is correct. A good way to do this is to initialize the bodies to a special-case starting condition, and then show that after a number of time steps the state of the grid exhibits symmetry or some other expected property. You need not prove your implementation's correctness in the literal sense. However, please annotate any simulation outputs clearly. Problem 2: Write Pthreads N-BodyFor this problem, you will use pthreads to parallelize your program from Problem 1. This program should take an additional command-line argument: the number of threads to use in the parallel section. It is only required that you parallelize the main portion of the simulation, but parallelizing the data generation phase of your n-body program is also worthwhile. You will not be penalized if you choose not to parallelize the initialization phase. To ensure that you have some practice with mutual exclusion, your parallel n-body program must use at least one lock. One way to satisfy this requirement is to implement your own barrier. For simplicity, you may assume that the number of bodies is evenly divisible by the number of threads. Problem 3: Analysis of N-BodyIn this section, you will analyze the performance of your two N-Body implementations. Modify your programs to measure the execution time of the parallel phase of execution. If you chose to parallelize the data generation phase, you may include that as well. Either way, make it clear exactly what you are measuring. Use of Unix's gethrtime() is recommended. Do not use the shell's built-in time command. Part A: Plot the normalized (versus the serial version of n-body) speedups of Program 2 on N=[1,2,4,8,16,32,64] threads for 512 bodies and 100 time steps. The value of dt is irrelevant to studying scalability: with the number of time steps held constant, it only affects the length of time simulated, not the duration of the simulation itself. Thus you may choose any value you like. We recommend that you use multiple trials in conjunction with some averaging strategy. Describe the procedure you used. Part B: Repeat Part A, but bind threads (see the processor_bind man page) to processors in the following orders and for N=[1,2,4,8,16,32,64]:
Obviously, you will not use all processors in all configurations. Plot the normalized speedup of B-1 through B-3 on a single graph. Comment on the shapes of the curves. Note: Lots of users trying to bind threads at the same time leads to no forward progress for any of you.... Please plan to run your programs well ahead of the deadline. Tips and Tricks
What to Hand InThis assignment will be peer reviewed. Please bring two copies of your homework to lecture; you will give these to the two NEWLY ASSIGNED peer review members. Your answers to the discussion questions should be typed up, handwritten notes are not acceptable. A tarball of your entire source code including a Makefile and a README file, should be emailed to your peer group members before the beginning of lecture. The README should include 1) directions for compiling your code, 2) directions for running your code, 3) any other comments. Use subject line [CS/ECE 757] Homework 1, so that email filters work properly. You must include:
|