The coming century is surely the century of data -- David Donoho (2000)
As a statistician, I am dedicated to developing statistical methodologies motivated by real-world applications, while enjoying great generalizability and adaptivity to various settings that keep pushing my methodological boundaries. The following is a word cloud generated from my recent research representatives.

1. Research on Data-driven Healthcare Solutions
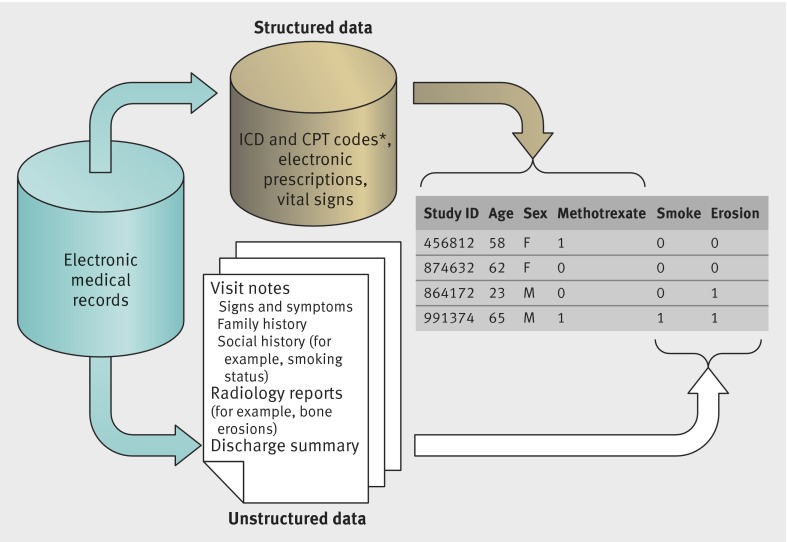 |
Electronic Health Records (EHR), with its increasingly widespread adoption, has opened up tremendous new research opportunities in data science leaning on modern statistical methods and computational techniques in hopes to improve public health and human wellbeing. My primary focus on EHR is to develop efficient methods for consensus learning using heterogeneous data across different EHR systems. |
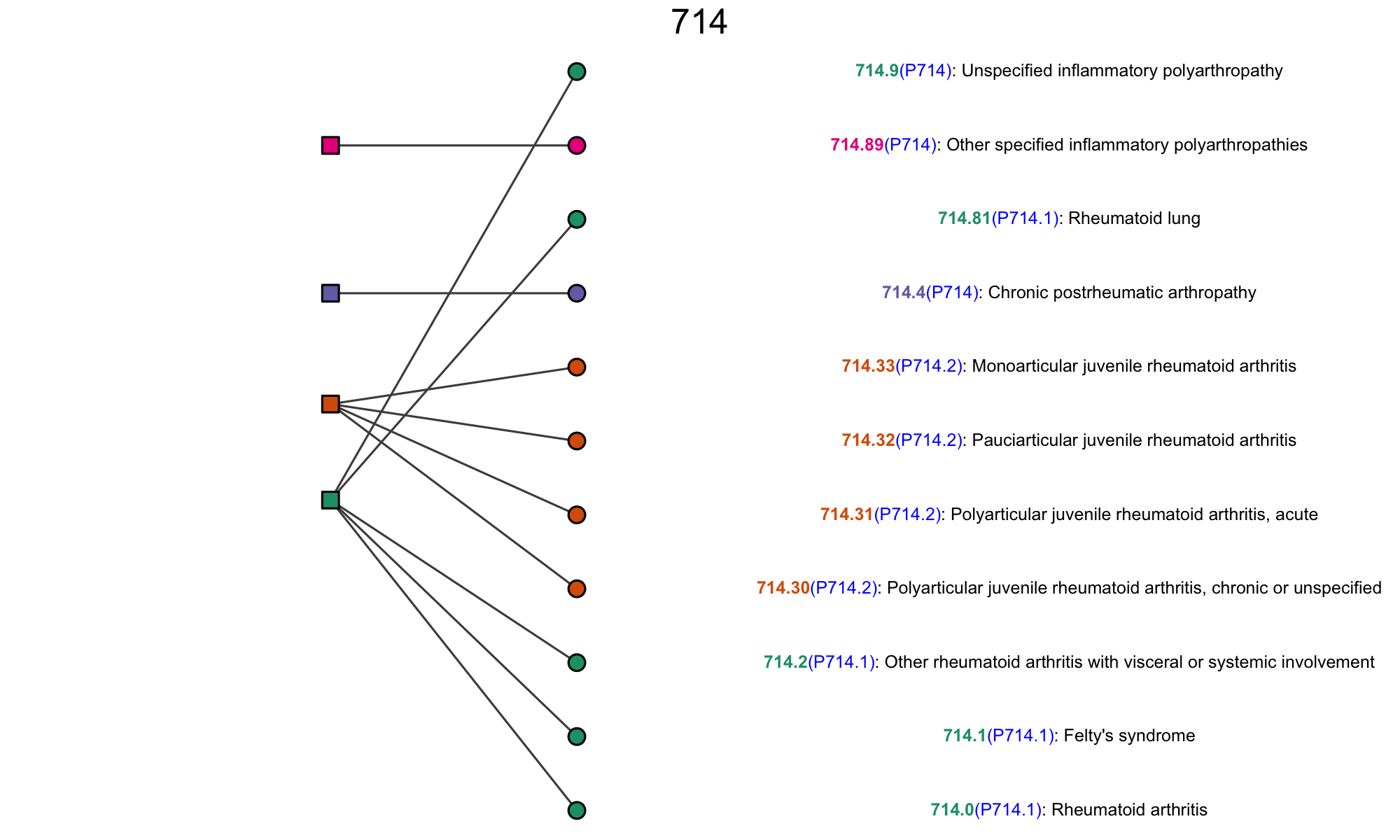
1. Data-driven clustering on medical concepts. A medical concept (e.g. diagnosis, prescription, symptom) is often described in various synonyms. For example, the International Classification of Disease (ICD) billing codes “714.0, 714.1, 714.2” describe slight variations of Rheumatoid Arthritis (RA). When it comes to research, the induced redundancy would largely hinder data integration for signal enhancement and complicate dimensionality reduction for knowledge discovery. Manual approaches are not scalable in step with the dramatic expansion on the universe of medical concepts. It is necessary to develop an efficient data-driven strategy resonating with the evolving human knowledge for up-to-date insights. The set of figures below exemplifies our efforts toward automated grouping using data from EHR systems and large claim data. A successful data-driven grouping structure can also serve my interests in learning high-quality clinical concept embeddings and their relations.
 |
 |
2. Efficient utilization on crowdsourced phenotyping predictions. To overcome the current phenotypic data scarcity, EHR-based phenotyping prediction is a prominent data-driven approach inferring whether a patient has a certain disease using his or her EHR. The yielded algorithms are not necessarily highly predictive in part due to a huge number of potentially irrelevant features collected. For example, Yu et al. (2015) proposed a screening approach to reduce candidate feature space. Recognizing experts among the crowd is the key to ensure prediction accuracy and the cornerstone of an effective ensemble learning method to enhance predicting power.

2. Research on Euclidean Distance Matrix and Low-dimensional Embeddings
It is a fundamental problem, in many contexts, to demystify internal relationships between a set of objects given only a (dis)similarity matrix, which yet may not be well-defined in that it does not correspond to a valid distance metric supporting subsequent statistical and computational analyses. Projecting to a Euclidean Distance Matrix (EDM) can reengage such efforts and provide a powerful tool for efficient visualization. In scenarios where objects indeed rest in a Euclidean space, the observed distance matrix is likely to be corrupted by noises or intrinsically high-dimensional. An appropriate low-rank approximation is needed for denoising to achieve efficient hidden relationship recovery. The animation below shows an example how distance shrinkage induces dimension reduction. The ribbon plots below illustrate the benefit of recovering a EDM corrupted under different levels of noise in improving protein 3D structure determination compared to the classical multidimensional scaling (MDS) approach(true structure colored in gold).
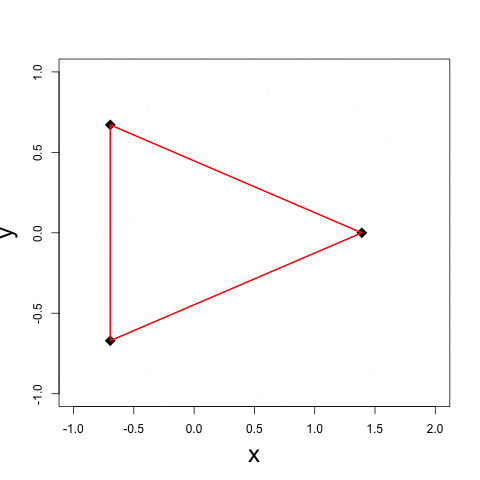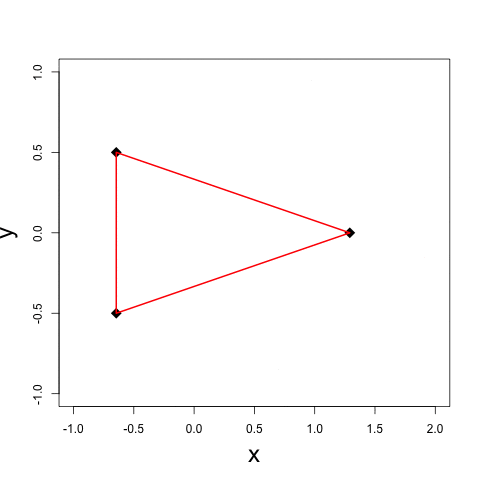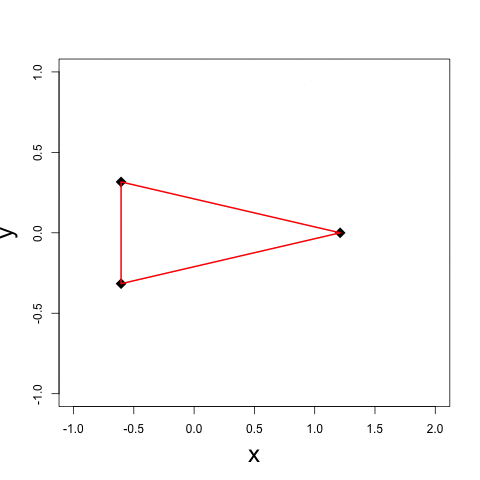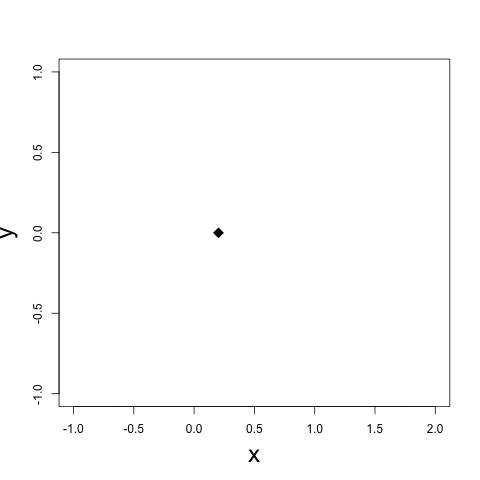 |
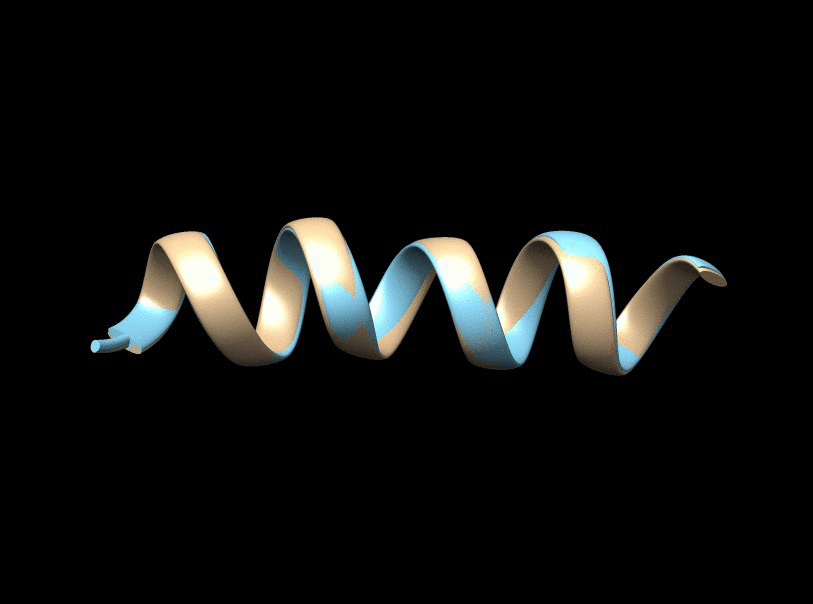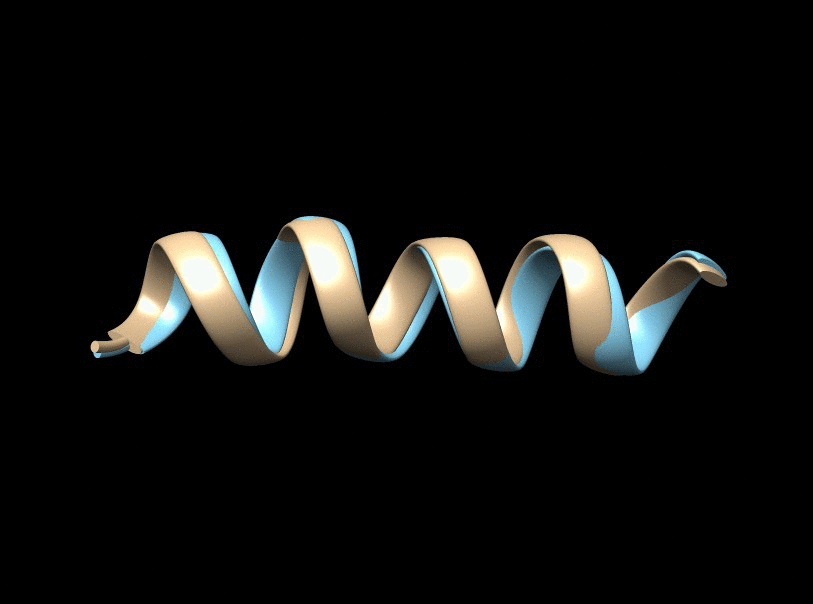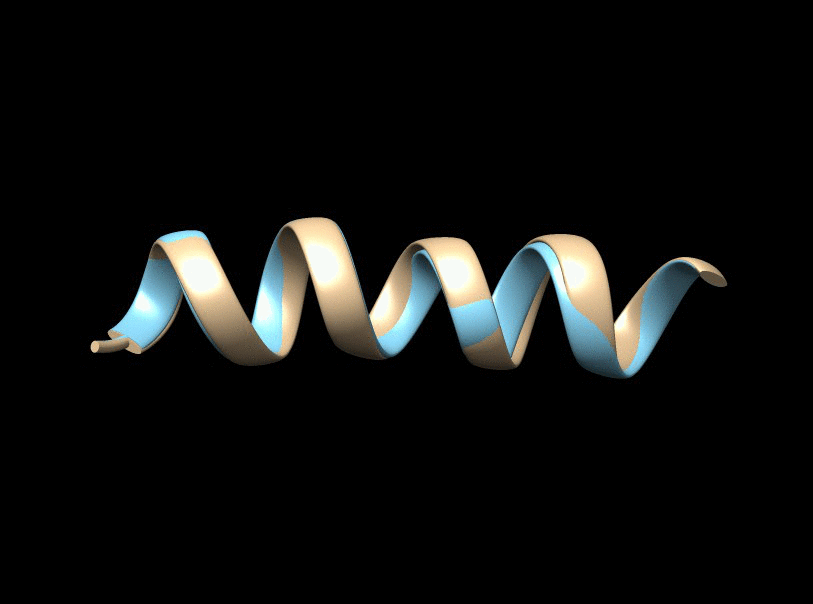 |
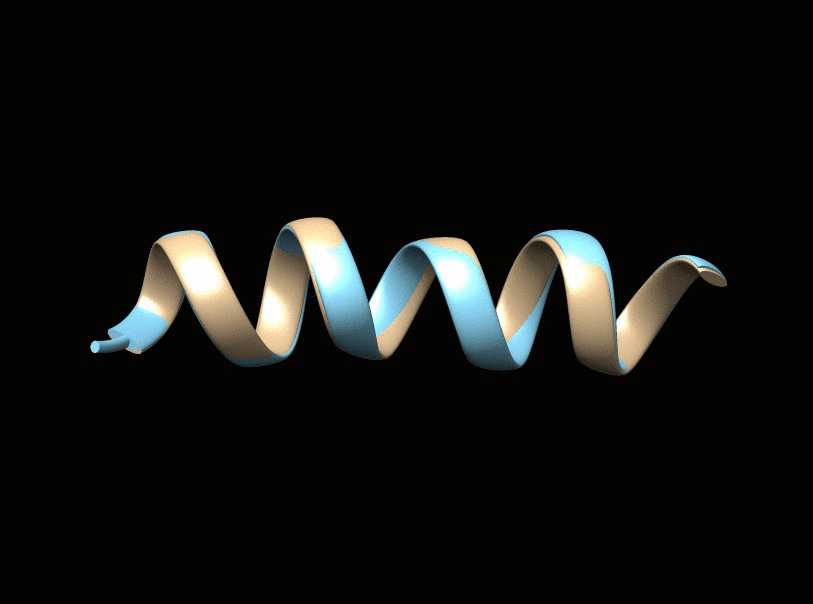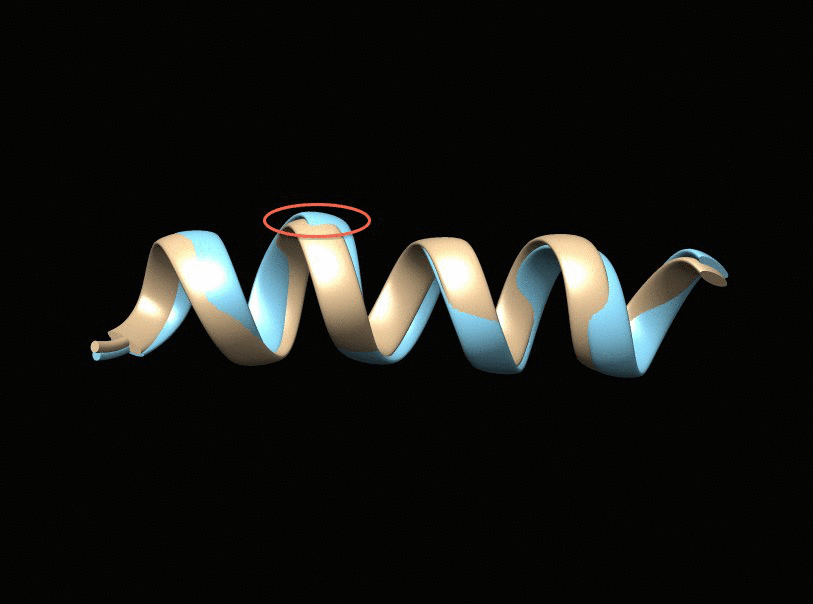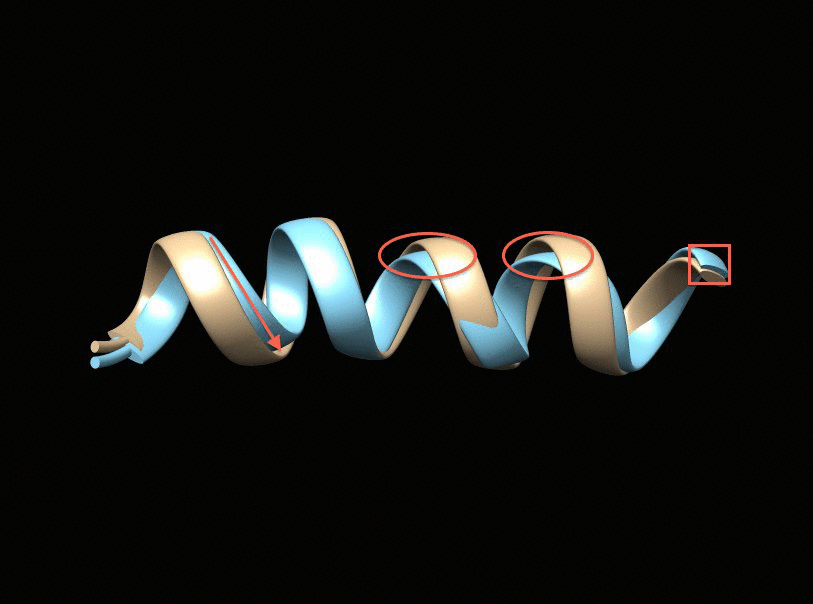 |