Just as the process abstraction beautifies the hardware by making a single CPU (or a small number of CPUs) appear to be many CPUs, one per “user,” the file system beautifies the hardware disk, making it appear to be a large number of disk-like objects called files. Like a disk, a file is capable of storing a large amount of data cheaply, reliably, and persistently. The fact that there are lots of files is one form of beautification: Each file is individually protected, so each user can have his own files, without the expense of requiring each user to buy his own disk. Each user can have lots of files, which makes it easier to organize persistent data. The filesystem also makes each individual file more beautiful than a real disk. At the very least, it erases block boundaries, so a file can be any length (not just a multiple of the block size) and programs can read and write arbitrary regions of the file without worrying about whether they cross block boundaries. Some systems (not Unix) also provide assistance in organizing the contents of a file.
Systems use the same sort of device (a disk drive) to support both virtual memory and files. The question arises why these have to be distinct facilities, with vastly different user interfaces. The answer is that they don't. In Multics, there was no difference whatsoever. Everything in Multics was a segment. The address space of each running process consisted of a set of segments (each with its own segment number), and the “file system” was simply a set of named segments. To access a segment from the file system, a process would pass its name to a system call that assigned a segment number to it. From then on, the process could read and write the segment simply by executing ordinary loads and stores. For example, if the segment was an array of integers, the program could access the ith number with a notation like a[i] rather than having to seek to the appropriate offset and then execute a read system call. If the block of the file containing this value wasn't in memory, the array access would cause a page fault, which was serviced as explained in the previous chapter.
This user-interface idea, sometimes called “single-level store,” is a great idea. So why is it not common in current operating systems? In other words, why are virtual memory and files presented as very different kinds of objects? There are possible explanations one might propose:
The real reason single-level store is not ubiquitous is probably a concern for efficiency. The usual file-system interface encourages a particular style of access: Open a file, go through it sequentially, copying big chunks of it to or from main memory, and then close it. While it is possible to access a file like an array of bytes, jumping around and accessing the data in tiny pieces, it is awkward. Operating system designers have found ways to implement files that make the common “file like” style of access very efficient. While there appears to be no reason in principle why memory-mapped files cannot be made to give similar performance when they are accessed in this way, in practice, the added functionality of mapped files always seems to pay a price in performance. Besides, if it is easy to jump around in a file, applications programmers will take advantage of it, overall performance will suffer, and the file system will be blamed.
Every file system provides some way to give a name to each file. We will consider only names for individual files here, and talk about directories later. The name of a file is (at least sometimes) meant to used by human beings, so it should be easy for humans to use. Different operating systems put different restrictions on names:
In general (not just in Unix) there are three ways of indicating the type of a file:
Systems support various access modes for operations on a file.
Unix records a fixed set of attributes in the meta-data associated with a file. If you want to record some fact about the file that is not included among the supported attributes, you have to use one of the tricks listed above for recording type information: encode it in the name of the file, put it into the body of the file itself, or store it in a file with a related name (e.g. “foo.attributes”). Other systems (notably MacOS and Windows NT) allow new attributes to be invented on the fly. In MacOS, each file has a resource fork, which is a list of (attribute-name, attribute-value) pairs. The attribute name can be any four-character string, and the attribute value can be anything at all. Indeed, some kinds of files put the entire “contents” of the file in an attribute and leave the “body” of the file (called the data fork) empty.
POSIX, a standard API (application programming interface) based on Unix, provides the following operations (among others) for manipulating files:
fd = open(name, operation) fd = creat(name, mode) status = close(fd) byte_count = read(fd, buffer, byte_count) byte_count = write(fd, buffer, byte_count) offset = lseek(fd, offset, whence) status = link(oldname, newname) status = unlink(name) status = stat(name, buffer) status = fstat(fd, buffer) status = utimes(name, times) status = chown(name, owner, group) or fchown(fd, owner, group) status = chmod(name, mode) or fchmod(fd, mode) status = truncate(name, size) or ftruncate(fd, size)Some types of arguments and results need explanation.
The read and write operations transfer data between a file and memory. The starting location in memory is indicated by the buffer parameter; the starting location in the file (called the seek pointer is wherever the last read or write left off. The result is the number of bytes transferred. For write it is normally the same as the byte_count parameter unless there is an error. For read it may be smaller if the seek pointer starts out near the end of the file. The lseek operation adjusts the seek pointer (it is also automatically updated by read and write). The specified offset is added to zero, the current seek pointer, or the current size of the file, depending on the value of whence.
The function link adds a new name (alias) to a file, while unlink removes a name. There is no function to delete a file; the system automatically deletes it when there are no remaining names for it.
The stat function retrieves meta-data about the file and puts it into a buffer (in a fixed, documented format), while the remaining functions can be used to update the meta-data: utimes updates time stamps, chown updates ownership, chmod updates protection information, and truncate changes the size (files can be make bigger by write, but only truncate can make them smaller). Most come in two flavors: one that take a file name and one that takes a descriptor for an open file.
To learn more details about any of these functions, type something like
man 2 lseek
to any Unix system. The ‘2’ means to look in section 2 of the manual,
where system calls are explained.
Other systems have similar operations, and perhaps a few more. For example, indexed or indexed sequential files would require a version of seek to specify a key rather than an offset. It is also common to have a separate append operation for writing to the end of a file.
We already talked about file names. One important feature that a file name should have is that it be unambiguous: There should be at most one file with any given name. The symmetrical condition, that there be at most one name for any given file, is not necessarily a good thing. Sometimes it is handy to be able to give multiple names to a file. When we consider implementation, we will describe two different ways to implement multiple names for a file, each with slightly different semantics. If there are a lot of files in a system, it may be difficult to avoid giving two files the same name, particularly if there are multiple uses independently making up names. One technique to assure uniqueness is to prefix each file name with the name (or user id) of the owner. In some early operating systems, that was the only assistance the system gave in preventing conflicts.
A better idea is the hierarchical directory structure, first introduced by Multics, then popularized by Unix, and now found in virtually every operating system. You probably already know about hierarchical directories, but I would like to describe them from an unusual point of view, and then explain how this point of view is equivalent to the more familiar version.
Each file is named by a sequence of names. Although all modern operating systems use this technique, each uses a different character to separate the components of the sequence when displaying it as a character string. Multics uses `>', Unix uses ‘/’, DOS and its descendants use ‘\’, and MacOS uses ':'. Sequences make it easy to avoid naming conflicts. First, assign a sequence to each user and only let him create files with names that start with that sequence. For example, I might be assigned the sequence (“usr”, “solomon”), written in Unix as /usr/solomon. So far, this is the same as just appending the user name to each file name. But it allows me to further classify my own files to prevent conflicts. When I start a new project, I can create a new sequence by appending the name of the project to the end of the sequence assigned to me, and then use this prefix for all files in the project. For example, I might choose /usr/solomon/cs537 for files associated with this course, and name them /usr/solomon/cs537/foo, /usr/solomon/cs537/bar, etc. As an extra aid, the system allows me to specify a “default prefix” and a short-hand for writing names that start with that prefix. In Unix, I use the system call chdir to specify a prefix, and whenever I use a name that does not start with ‘/’, the system automatically adds that prefix.
It is customary to think of the directory system as a directed graph, with names on the edges. Each path in the graph is associated with a sequence of names, the names on the edges that make up the path. For that reason, the sequence of names is usually called a path name. One node is designated as the root node, and the rule is enforced that there cannot be two edges with the same name coming out of one node. With this rule, we can use path name to name nodes. Start at the root node and treat the path name as a sequence of directions, telling us which edge to follow at each step. It may be impossible to follow the directions (because they tell us to use an edge that does not exist), but if is possible to follow the directions, they will lead us unambiguously to one node. Thus path names can be used as unambiguous names for nodes. In fact, as we will see, this is how the directory system is actually implemented. However, I think it is useful to think of “path names” simply as long names to avoid naming conflicts, since it clear separates the interface from the implementation.
We will assume that all the blocks of the disk are given block numbers starting at zero and running through consecutive integers up to some maximum. We will further assume that blocks with numbers that are near each other are located physically near each other on the disk (e.g., same cylinder) so that the arithmetic difference between the numbers of two blocks gives a good estimate how long it takes to get from one to the other. First let's consider how to represent an individual file. There are (at least!) four possibilities:
Both the space overhead (the percentage of the space taken up by pointers) and the time overhead (the percentage of the time seeking from one place to another) can be decreased by using larger blocks. The hardware designer fixes the block size (which is usually quite small) but the software can get around this problem by using “virtual” blocks, sometimes called clusters. The OS simply treats each group of (say) four continguous phyical disk sectors as one cluster. Large, clusters, particularly if they can be variable size, are sometimes called extents. Extents can be thought of as a compromise between linked and contiguous allocation.
The main problem with this approach is that the index array I can get quite large with modern disks. For example, consider a 2 GB disk with 2K blocks. There are million blocks, so a block number must be at least 20 bits. Rounded up to an even number of bytes, that's 3 bytes--4 bytes if we round up to a word boundary--so the array I is three or four megabytes. While that's not an excessive amount of memory given today's RAM prices, if we can get along with less, there are better uses for the memory.
The only problem with this idea is that it wastes space for small files. Any file with more than one block needs at least one indirect block to store its block numbers. A 4K file would require three 2K blocks, wasting up to one third of its space. Since many files are quite small, this is serious problem. The Unix solution is to use a different kind of “block” for the root of the tree.
An index node (or inode for short) contains almost all the meta-data about a file listed above: ownership, permissions, time stamps, etc. (but not the file name). Inodes are small enough that several of them can be packed into one disk block. In addition to the meta-data, an inode contains the block numbers of the first few blocks of the file. What if the file is too big to fit all its block numbers into the inode? The earliest version of Unix had a bit in the meta-data to indicate whether the file was “small” or “big.” For a big file, the inode contained the block numbers of indirect blocks rather than data blocks. More recent versions of Unix contain pointers to indirect blocks in addition to the pointers to the first few data blocks. The inode contains pointers to (i.e., block numbers of) the first few blocks of the file, a pointer to an indirect block containing pointers to the next several blocks of the file, a pointer to a doubly indirect block, which is the root of a two-level tree whose leaves are the next blocks of the file, and a pointer to a triply indirect block. A large file is thus a lop-sided tree. (See Figure 11.19 on page 384).
A real-life example is given by the Solaris 2.5 version of Unix. Block numbers are four bytes and the size of a block is a parameter stored in the file system itself, typically 8K (8192 bytes), so 2048 pointers fit in one block. An inode has direct pointers to the first 12 blocks of the file, as well as pointers to singly, doubly, and triply indirect blocks. A file of up to 12+2048+2048*2048 = 4,196,364 blocks or 34,376,613,888 bytes (about 32 GB) can be represented without using triply indirect blocks, and with the triply indirect block, the maximum file size is (12+2048+2048*2048+2048*2048*2048)*8192 = 70,403,120,791,552 bytes (slightly more than 246 bytes, or about 64 terabytes). Of course, for such huge files, the size of the file cannot be represented as a 32-bit integer. Modern versions of Unix store the file length as a 64-bit integer, called a “long” integer in Java. An inode is 128 bytes long, allowing room for the 15 block pointers plus lots of meta-data. 64 inodes fit in one disk block. Since the inode for a file is kept in memory while the file is open, locating an arbitrary block of any file requires reading at most three I/O operations, not counting the operation to read or write the data block itself.
A directory is simply a table mapping character-string human-readable names to information about files. The early PC operating system CP/M shows how simple a directory can be. Each entry contains the name of one file, its owner, size (in blocks) and the block numbers of 16 blocks of the file. To represent files with more than 16 blocks, CP/M used multiple directory entries with the same name and different values in a field called the extent number. CP/M had only one directory for the entire system.
DOS uses a similar directory entry format, but stores only the first block number of the file in the directory entry. The entire file is represented as a linked list of blocks using the disk index scheme described above. All but the earliest version of DOS provide hierarchical directories using a scheme similar to the one used in Unix.
Unix has an even simpler directory format. A directory entry contains only two fields: a character-string name (up to 14 characters) and a two-byte integer called an inumber, which is interpreted as an index into an array of inodes in a fixed, known location on disk. All the remaining information about the file (size, ownership, time stamps, permissions, and an index to the blocks of the file) are stored in the inode rather than the directory entry. A directory is represented like any other file (there's a bit in the inode to indicate that the file is a directory). Thus the inumber in a directory entry may designate a “regular” file or another directory, allowing arbitrary graphs of nodes. However, Unix carefully limits the set of operating system calls to ensure that the set of directories is always a tree. The root of the tree is the file with inumber 1 (some versions of Unix use other conventions for designating the root directory). The entries in each directory point to its children in the tree. For convenience, each directory also two special entries: an entry with name “..”, which points to the parent of the directory in the tree and an entry with name “.”, which points to the directory itself. Inumber 0 is not used, so an entry is marked “unused” by setting its inumber field to 0.
The algorithm to convert from a path name to an inumber might be written
in Java as
int namei(int current, String[] path) {
for (int i = 0; i<path.length; i++) {
if (inode[current].type != DIRECTORY)
throw new Exception("not a directory");
current = nameToInumber(inode[current], path[i]);
if (current == 0)
throw new Exception("no such file or directory");
}
return current;
}
The procedure nameToInumber(Inode node, String name) (not shown)
reads through the directory file represented by the inode node, looks
for an entry matching the given name and returns the inumber contained
in that entry.
The procedure namei walks the directory tree,
starting at a given inode and following a path described by a sequence of
strings. There is a procedure with this name in the Unix kernel.
Files are always specified in Unix system calls by a character-string
path name. You can learn the inumber of a file if you like, but you
can't use the inumber when talking to the Unix kernel.
Each system call that has a path name as an argument uses namei
to translate it to an inumber.
If the argument is an absolute path name (it starts with ‘/’), namei
is called with current == 1. Otherwise, current is the
current working directory.
Since all the information about a file except its name is stored in the inode, there can be more than one directory entry designating the same file. This allows multiple aliases (called links) for a file. Unix provides a system call link(old-name, new-name) to create new names for existing files. The call link("/a/b/c", "/d/e/f") works something like this:
if (namei(1, parse("/d/e/f")) != 0)
throw new Exception("file already exists");
int dir = namei(1, parse("/d/e")):
if (dir==0 || inode[dir].type != DIRECTORY)
throw new Exception("not a directory");
int target = namei(1, parse("/a/b/c"));
if (target==0)
throw new Exception("no such directory");
if (inode[target].type == DIRECTORY)
throw new Exception("cannot link to a directory");
addDirectoryEntry(inode[dir], target, "f");
The procedure parse (not shown here) is assumed to break up
a path name into its components.
If, for example, /a/b/c resolves to inumber 123, the
entry (123, "f") is added to
directory file designated by "/d/e".
The result is that both "/a/b/c" and "/d/e/f" resolve to
the same file (the one with inumber 123).
We have seen that a file can have more than one name. What happens if it has no names (does not appear in any directory)? Since the only way to name a file in a system call is by a path name, such a file would be useless. It would consume resources (the inode and probably some data and indirect blocks) but there would be no way to read it, write to it, or even delete it. Unix protects against this “garbage collection” problem by using reference counts. Each inode contains a count of the number of directory entries that point to it. “User” programs are not allowed to update directories directly. System calls that add or remove directory entries (creat, link, mkdir, rmdir, etc) update these reference counts appropriately. There is no system call to delete a file, only the system call unlink(name) which removes the directory entry corresponding to name. If the reference count of an inode drops to zero, the system automatically deletes the files and returns all of its blocks to the free list.
We saw before that the reference counting algorithm for garbage collection has a fatal flaw: If there are cycles, reference counting will fail to collect some garbage. Unix avoids this problem by making sure cycles cannot happen. The system calls are designed so that the set of directories will always be a single tree rooted at inode 1: mkdir creates a new empty (except for the . and .. entries) as a leaf of the tree, rmdir is only allowed to delete a directory that is empty (except for the . and .. entries), and link is not allowed to link to a directory. Because links to directories are not allowed, the only place the file system is not a tree is at the leaves (regular files) and that cannot introduce cycles.
Although this algorithm provides the ability to create aliases for files in a simple and secure manner, it has several flaws:
class DirectoryEntry {
int inumber;
String name;
}
String cwd() {
FileInputStream thisDir = new FileInputStream(".");
int thisInumber = nameToInumber(thisDir, ".");
getPath(".", thisInumber);
}
String getPath(String currentName, int currentInumber) {
String parentName = currentName + "/..";
FileInputSream parent = new FileInputStream(parentName);
int parentInumber = nameToInumber(parent, ".");
String fname = inumberToName(parent, currentInumber);
if (parentInumber == 1)
return "/" + fname;
else
return getPath(parentInumber, parentName) + "/" + fname;
}
The procedure nameToInumber is similar to the procedure with
the same name described above, but takes an
InputStream as an argument rather than an inode.
Many versions of Unix allow a program to open a directory for reading
and read its contents just like any other file.
In such systems, it would be easy to write
nameToInumber as a user-level procedure if you know the format
of a directory.2
The procedure inumberToName is similar, but searches for an entry
containing a particular inumber and returns the name field of the
entry.
To get around the limitations with the original Unix notion of links,
more recent versions of Unix introduced the notion of a symbolic link
(to avoid confusion, the original kind of link, described in
the previous section, is sometimes
called a hard link).
A symbolic link is a new type of file, distinguished by a code in the inode
from directories, regular files, etc.
When the namei procedure that translates path names to inumbers
encounters a symlink, it treats the contents of the file as a pathname and
uses it to continue the translation.
If the contents of the file is a relative path name (it does not start with
a slash), it is interpreted relative to the directory containing the
link itself, not the current working directory of the process doing the
lookup.
int namei(int current, String[] path) {
for (int i = 0; i<path.length; i++) {
if (inode[current].type != DIRECTORY)
throw new Exception("not a directory");
parent = current;
current = nameToInumber(inode[current], path[i]);
if (current == 0)
throw new Exception("no such file or directory");
if (inode[current].type == SYMLINK) {
String link = getContents(inode[current]);
String[] linkPath = parse(link);
if (link.charAt(0) == '/')
current = namei(1, linkPath);
else
current = namei(parent, linkPath);
if (current == 0)
throw new Exception("no such file or directory");
}
}
return current;
}
The only change from the previous version of this
procedure is the addition of the while loop.
Any time the procedure encounters a node of type SYMLINK, it
recursively calls itself to translate the contents of the file, interpreted
as a path name, into an inumber.
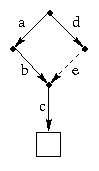
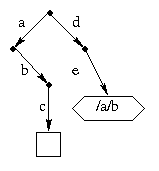
Although the implementation looks complicated, it does just what you would expect in normal situations. For example, suppose there is an existing file named /a/b/c and an existing directory /d. Then the the command
ln -s /a/b /d/e
makes the path name /d/e a synonym for /a/b, and also makes
/d/e/c a synonym for /a/b/c.
From the user's point of view, the the picture looks like this:
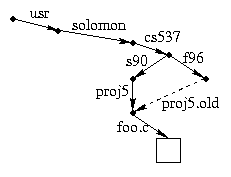
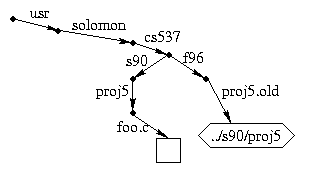
Here's a more elaborate example that illustrates symlinks with relative path names. Suppose I have an existing directory /usr/solomon/cs537/s90 with various sub-directories and I am setting up project 5 for this semester. I might do something like this:
cd /usr/solomon/cs537
mkdir f96
cd f96
ln -s ../s90/proj5 proj5.old
cat proj5.old/foo.c
cd /usr/solomon/cs537
cat f96/proj5.old/foo.c
cat s90/proj5/foo.c
Logically, the situation looks like this:
The added flexibility of symlinks over hard links comes at the expense of less security. Symlinks are neither required nor guaranteed to point to valid files. You can remove a file out from under a symlink, and in fact, you can create a symlink to a non-existent file. Symlinks can also have cycles. For example, this works fine:
cd /usr/solomon
mkdir bar
ln -s /usr/solomon foo
ls /usr/solomon/foo/foo/foo/foo/bar
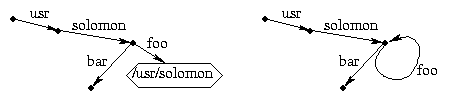
cd foo
cd ..
to cancel each other out.
But in the last example, the commands
cd /usr/solomon
cd foo
cd ..
would leave you in the directory /usr.
Some shell programs treat cd specially and remember what alias
you used to get to the current directory.
After cd /usr/solomon; cd foo; cd foo, the current directory is
/usr/solomon/foo/foo, which is an alias for /usr/solomon, but
the command cd .. is treated as if you had typed
cd /usr/solomon/foo.
What if your computer has more than one disk? In many operating systems (including DOS and its descendants) a pathname starts with a device name, as in C:\usr\solomon (by convention, C is the name of the default hard disk). If you leave the device prefix off a path name, the system supplies a default current device similar to the current directory. Unix allows you to glue together the directory trees of multiple disks to create a single unified tree. There is a system call
mount(device, mount_point)
where device names a particular disk drive and mount_point
is the path name of an existing node in the current directory tree (normally
an empty directory). The result is similar to a hard link: The mount point
becomes an alias for the root directory of the indicated disk.
Here's how it works: The kernel maintains a table of existing mounts
represented as (device1, inumber, device2) triples.
During namei, whenever the current (device, inumber) pair matches
the first two fields in one of the entries, the current device and inumber
become device2 and 1, respectively.
Here's the expanded code:
int namei(int curi, int curdev, String[] path) {
for (int i = 0; i<path.length; i++) {
if (disk[curdev].inode[curi].type != DIRECTORY)
throw new Exception("not a directory");
parent = curi;
curi = nameToInumber(disk[curdev].inode[curi], path[i]);
if (curi == 0)
throw new Exception("no such file or directory");
if (disk[curdev].inode[curi].type == SYMLINK) {
String link = getContents(disk[curdev].inode[curi]);
String[] linkPath = parse(link);
if (link.charAt(0) == '/')
current = namei(1, curdev, linkPath);
else
current = namei(parent, curdev, linkPath);
if (current == 0)
throw new Exception("no such file or directory");
}
int newdev = mountLookup(curdev, curi);
if (newdev != -1) {
curdev = newdev;
curi = 1;
}
}
return current;
}
In this code, we assume that mountLookup searches the mount table
for matching entry, returning -1 if no matching entry is found.
There is a also a special case (not shown here) for “..” so that
the “..” entry in the root directory of a mounted disk behaves
like a pointer to the parent directory of the mount point.
The Network File System (NFS) from Sun Microsystems extends this idea to allow you to mount a disk from a remote computer. The device argument to the mount system call names the remote computer as well as the disk drive and both pieces of information are put into the mount table. Now there are three pieces of information to define the “current directory”: the inumber, the device, and the computer. If the current computer is remote, all operations (read, write, creat, delete, mkdir, rmdir, etc.) are sent as messages to the remote computer. Information about remote open files, including a seek pointer and the identity of the remote machine, is kept locally. Each read or write operation is converted locally to one or more requests to read or write blocks of the remote file. NFS caches blocks of remote files locally to improve performance.
I said that the Unix mount system call has the name of a disk device as an argument. How do you name a device? The answer is that devices appear in the directory tree as special files. An inode whose type is “special” (as opposed to “directory,” “symlink,” or “regular”) represents some sort of I/O device. It is customary to put special files in the directory /dev, but since it is the inode that is marked “special,” they can be anywhere. Instead of containing pointers to disk blocks, the inode of a special file contains information (in a machine-dependent format) about the device. The operating system tries to make the device look as much like a file as possible, so that ordinary programs can open, close, read, or write the device just like a file.
Some devices look more like real file than others. A disk device looks exactly like a file. Reads return whatever is on the disk and writes can scribble anywhere on the disk. For obvious security reasons, the permissions for the raw disk devices are highly restrictive. A tape drive looks sort of like a disk, but a read will return only the next physical block of data on the device, even if more is requested.
The special file /dev/tty represents the terminal. Writes to /dev/tty display characters on the screen. Reads from /dev/tty return characters typed on the keyboard. The seek operation on a device like /dev/tty updates the seek pointer, but the seek pointer has no effect on reads or writes. Reads of /dev/tty are also different from reads of a file in that they may return fewer bytes than requested: Normally, a read will return characters only up through the next end-of-line. If the number of bytes requested is less than the length of the line, the next read will get the remaining bytes. A read call will block the caller until at least one character can be returned. On machines with more than one terminal, there are multiple terminal devices with names like /dev/tty0, /dev/tty1, etc.
Some devices, such as a mouse, are read-only. Write operations on such devices have no effect. Other devices, such as printers, are write-only. Attempts to read from them give an end-of-file indication (a return value of zero). There is special file called /dev/null that does nothing at all: reads return end-of-file and writes send their data to the garbage bin. (New EPA rules require that this data be recycled. It is now used to generate federal regulations and other meaningless documents.) One particularly interesting device is /dev/mem, which is an image of the memory space of the current process. In a sense, this device is the exact opposite of memory-mapped files. Instead of making a file look like part of virtual memory, it makes virtual memory look like a device.
This idea of making all sorts of things look like files can be very powerful. Some versions of Unix make network connections look like files. Some versions have a directory with one special file for each active process. You can read these files to get information about the states of processes. If you delete one of these files, the corresponding process is killed. Another idea is to have a directory with one special file for each print job waiting to be printed. Although this idea was pioneered by Unix, it is starting to show up more and more in other operating systems.
1Note that we are referring here to a single pathname component.
2The Solaris version of Unix on our workstations has a special system call for reading directories, so this code couldn't be written in Java without resorting to native methods.