# Midterm M2A
📗 Enter your ID (the wisc email ID without @wisc.edu) here: and click 1,2,3,4,5,6,7,8,9,10 1
📗 The same ID should generate the same set of questions. Your answers are not saved when you close the browser. You could print the page: , solve the problems, then enter all your answers at the end.
📗 Please do not refresh the page: your answers will not be saved. You can save and load your answers (only fill-in-the-blank questions) using the buttons at the bottom of the page.
# Warning: please enter your ID before you start!
# Question 10
📗 [4 points] Given a linear SVM (Support Vector Machine) that perfectly classifies a set of training data containing positive examples and negative examples with 2 support vectors. After adding one more positively labeled training example and retraining the SVM, what is the maximum possible number of support vectors possible in the new SVM.
Hint
See Fall 2019 Final Q7, Fall 2019 Final Q8.📗 Answer: .
📗 [4 points] You are given a training set of five points and their 2-class classifications (+ or -): (, +), (, +), (, -), (, -), (, -). What is the decision boundary associated with this training set using 3NN (3 Nearest Neighbor)?
Hint
See Spring 2017 Midterm Q6. The decision boundary is the threshold such that all points on its left is classified as positive, and all points on its right is classified as negative. The threshold should be equidistant from the first and fourth points (i.e. the midpoint between the first and fourth points).📗 Answer: .
📗 [2 points] In your day vacation, the counts of days are:
| rainy | warm | bighorn (saw sheep) | days |
| N | N | N | |
| N | N | Y | |
| N | Y | N | |
| N | Y | Y | |
| Y | N | N | |
| Y | N | Y | |
| Y | Y | N | |
| Y | Y | Y |
Use maximum likelihood estimate (no smoothing), estimate the probability that P(bighorn = | rainy = , warm = )?
Hint
See Fall 2017 Final Q3, Fall 2006 Final Q19, Fall 2005 Final Q19. For example, the maximum likelihood estimate of \(\mathbb{P}\left\{A | \neg B, C\right\} = \dfrac{\mathbb{P}\left\{A, \neg B, C\right\}}{\mathbb{P}\left\{\neg B, C\right\}}\), for binary variables \(A, B, C\), is \(\dfrac{n_{A, \neg B, C}}{n_{A, \neg B, C} + n_{\neg A, \neg B, C}}\).📗 Answer: .
📗 [4 points] Given the following transition matrix for a bigram model with words "I" (label 0), "am" (label 1) and "Groot" (label 2): . Row \(i\) column \(j\) is \(\mathbb{P}\left\{w_{t} = j | w_{t-1} = i\right\}\). Two uniform random numbers between 0 and 1 are generated to simulate the words after "I", say \(u_{1}\) = and \(u_{2}\) = . Using the CDF (Cumulativ Distribution Function) inversion method (inverse transform method), which two words are generated? Enter two integer labels (0, 1, or 2), not strings.
Hint
📗 Answer (comma separated vector): .
📗 [4 points] What is the convolution between the image and the filter using zero padding? The flipped filter is .
Hint
Use the convolution formula between matrix X and a k by k filter W that \(A_{i,j} = \displaystyle\sum_{s=-k}^{k} \displaystyle\sum_{t=-k}^{k} W_{s,t} X_{i-s,j-t}\) for every element (i,j) of the matrix X. Intuitively, flip the filter and take the dot product between the filter and the submatrix centered at each (i,j) to compute the convolution at (i,j).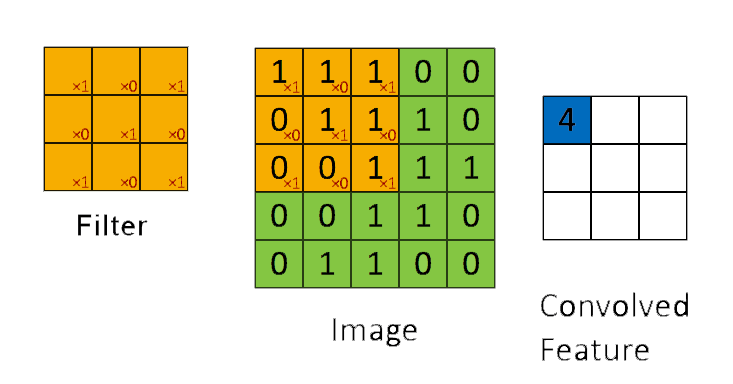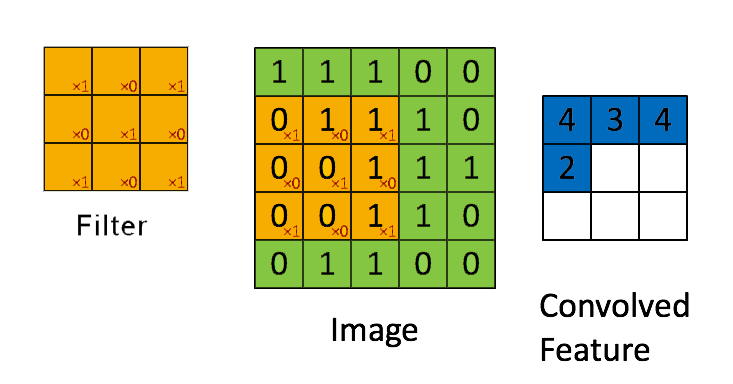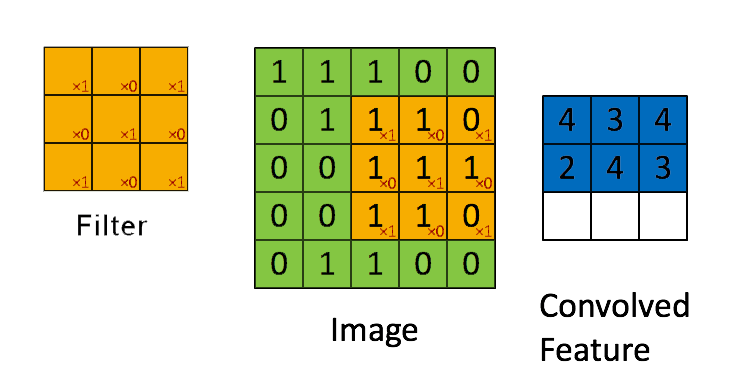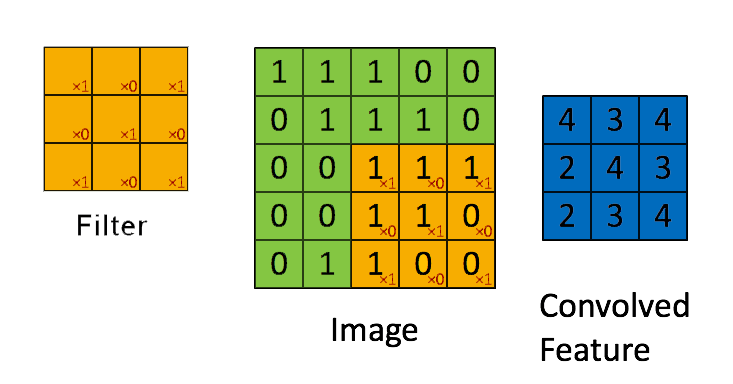
📗 Answer (matrix with multiple lines, each line is a comma separated vector): .
📗 [4 points] In a convolutional neural network, suppose the activation map of a convolution layer is . What is the activation map after a non-overlapping (stride 2) 2 by 2 average-pooling layer?
Hint
Take the maximum (or average) of each 2 by 2 submatrix and put them in a larger matrix.📗 Answer (matrix with multiple lines, each line is a comma separated vector): .
📗 [4 points] Consider a kernel \(K\left(x_{i_{1}}, x_{i_{2}}\right)\) = + + , where both \(x_{i_{1}}\) and \(x_{i_{2}}\) are 1D positive real numbers. What is the feature vector \(\varphi\left(x_{i}\right)\) induced by this kernel evaluated at \(x_{i}\) = ?
Hint
See Fall 2009 Final Q2. Write \(K\left(x, y\right)\) as the dot product of \(\varphi\left(x\right)\) and \(\varphi\left(y\right)\) (guess and check). Then substitute the value of \(x\) into the vector.📗 Answer (comma separated vector): .
📗 [3 points] A decision tree has depth \(d\) = (a decision tree where the root is a leaf node has \(d\) = 0). All its internal node have \(b\) = children. The tree is also complete, meaning all leaf nodes are at depth \(d\). If we require each leaf node to contain at least training examples, what is the minimum size of the training set?
Hint
See Fall 2014 Midterm Q9, Fall 2012 Final Q6. The total number of leaf nodes in a complete tree is \(b^{d}\), and if at least \(n\) training examples are needed in each one of them, since the same training example cannot appear in multiple subtrees, there should be at least \(n b^{d}\) training examples in total.📗 Answer: .
📗 [4 points] A convolutional neural network has input image of size x that is connected to a convolutional layer that uses a x filter, zero padding of the image, and a stride of 1. There are activation maps. (Here, zero-padding implies that these activation maps have the same size as the input images.) The convolutional layer is then connected to a pooling layer that uses x max pooling, a stride of (non-overlapping, no padding) of the convolutional layer. The pooling layer is then fully connected to an output layer that contains output units. There are no hidden layers between the pooling layer and the output layer. How many different weights must be learned in this whole network, not including any bias.
Hint
See Fall 2019 Final Q15, Spring 2018 Midterm Q8 Q9 Q10 Q11, Fall 2017 Final Q5, Spring 2017 Final Q5, Fall 2017 Midterm Q9, Fall 2017 Midterm Q11. Each k by k filter in the first layer has \(k \times k\) weights, the number of such filters depend on the number of activation maps in the next layer. The pooling layers do not have weights, but the number of units in the next layer depends on the pooling filter size (reduces the units by a factor of the filter size). The last layer is fully connected, so the number of weights is the product between the number of units in the previous layer and the number of output units.📗 Answer: .
# Warning: remember to submit this on Canvas!
📗 Please copy and paste the text between the *s (not including the *s) and submit it on Canvas, M2A.
📗 Please save a copy as text file using the button or just copy and paste it into a text file.
📗 You could load your answers using the button from the text field:
Last Updated: July 14, 2024 at 8:37 PM