Prev: L6, Next: L8
Zoom: Link, TopHat: Link, GoogleForm: Link, Piazza: Link, Feedback: Link.
Tools
📗 You can expand all TopHat Quizzes and Discussions: , and print the notes: , or download all text areas as text file: .
📗 For visibility, you can resize all diagrams on page to have a maximum height that is percent of the screen height: .
📗 Calculator:
📗 Canvas:
pen
# Computer Vision Tasks
📗 Unsupervised:
➩ Image segmentation.
📗 Supervised:
➩ Image colorization.
➩ Image reconstruction.
➩ Image synthesis.
➩ Image captioning.
➩ Object detection and tracking.
➩ Medical image analysis.
# Convolution
📗 Pixels are not independent of their neighbors. Ignoring the dependence is inappropriate for most computer vision tasks.
📗 Neighboring pixel intensities can be combined to create one feature that captures the information in the region around the pixel.
📗 Linearly combining pixels in a rectangular region is called convolution: Wikipedia.
➩ The convolution of an \(m \times m\) matrix (representing a training image indexed \(i\)) \(X_{i}\) with a \(\left(2 k + 1\right) \times \left(2 k + 1\right)\) filter \(W = \left[W_{s t}\right]_{s = -k, ..., k, t = -k, ..., k}\) is an \(m \times m\) matrix \(A_{i} = X_{i} \star W\), where the row \(r\) column \(c\) entry is given by \(\left[A_{i}\right]_{r c} = \displaystyle\sum_{s = -k}^{k} \displaystyle\sum_{t = -k}^{k} \left[X_{i}\right]_{r + t, c + s} W_{-s, -t}\).
➩ Technical note: the definition here flips the filter, for example the filter \(\begin{bmatrix} 1 & 2 & 3 \\ 4 & 5 & 6 \\ 7 & 8 & 9 \end{bmatrix}\) is flipped to \(\begin{bmatrix} 9 & 8 & 7 \\ 6 & 5 & 4 \\ 3 & 2 & 1 \end{bmatrix}\) before linear combination with the image. Similar linear combination without flipping the filter is called cross-correlation.
➩ The convolution filter is also called "kernel", but different from the kernel matrix for SVMs.
Math Note
📗 Convolution between two 1D vectors is also defined: the convolution of a vector \(x_{i} = \left(x_{i 1}, x_{i 2}, ..., x_{i m}\right)\) with a filter \(w = \left(w_{-k}, w_{-k + 1}, ..., w_{k-1}, w_{k}\right)\) is: \(a_{i} = \left(a_{i 1}, a_{i 2}, ..., a_{i m}\right) = x \star w\), where \(a_{i j} = w_{-k} x_{i \left(j + k\right)} + w_{-k + 1} x_{i \left(j + k - 1\right)} + ... + w_{k} x_{i \left(j - k\right)}\) for \(j = 1, 2, ..., m\).
📗 3D convolution can be defined in a similar way.
Example
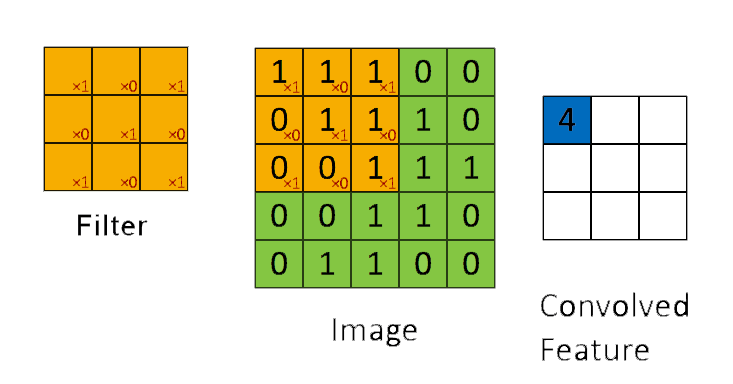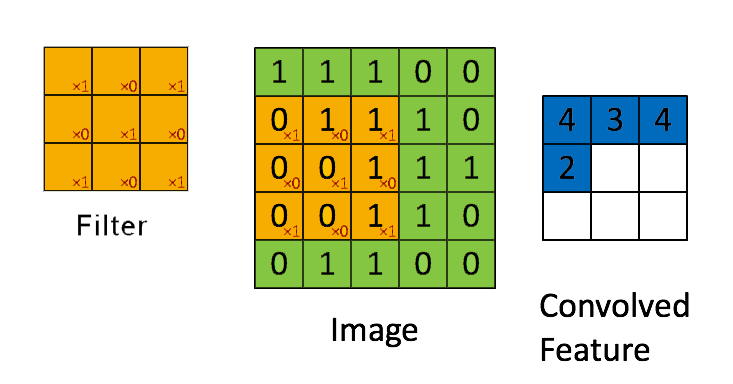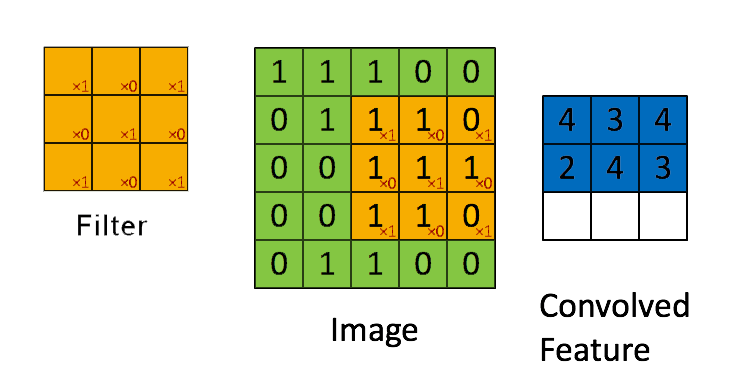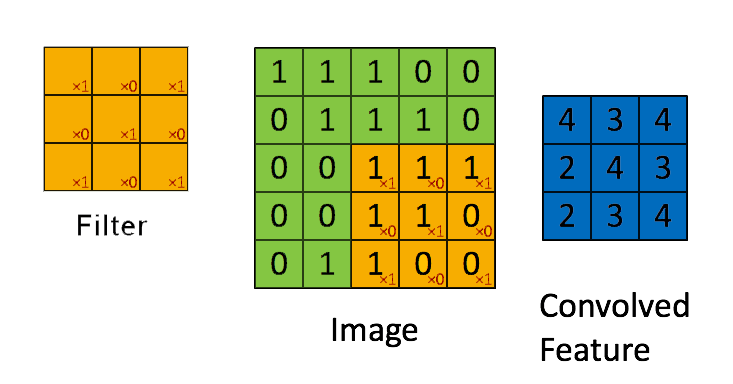
In-class Discussion
📗 [1 points] Upload an image and try one of the following filters: . Image:
![]() 1. Click on the image to perform convolution with this filter: .
1. Click on the image to perform convolution with this filter: .
For Gaussian filter: size = , \(\sigma\) = . 0
In-class Quiz
ID:📗 [4 points] What is the convolution between the image and the filter using zero padding? Remember to flip the filter first.
📗 Answer (matrix with multiple lines, each line is a comma separated vector): .
Other students' answers:
# Traditional Computer Vision
📗 Traditional computer vision algorithms use engineered features for images based on image gradients.
➩ Image gradients are changes in pixel intensity due to the change in the location of the pixel: Wikipedia.
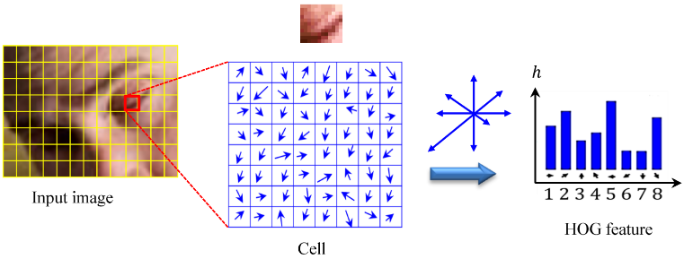
➩ Histogram of Gradients (HOG) can be used as a features for images and is often combined with SVM for face detection and recognition tasks: Wikipedia.
Math Note
📗 Image gradients can be computed (approximated) by convolution with the following filters: \(\nabla_{x} I = W_{x} \star I\) and \(\nabla_{y} I = W_{y} \star I\).
➩ (Discrete) derivative filter: \(W_{x} = \begin{bmatrix} -1 & 0 & 1 \\ -1 & 0 & 1 \\ -1 & 0 & 1 \end{bmatrix}\) and \(W_{y} = \begin{bmatrix} -1 & -1 & -1 \\ 0 & 0 & 0 \\ 1 & 1 & 1 \end{bmatrix}\).
➩ Sobel filters: \(W_{x} = \begin{bmatrix} -1 & 0 & 1 \\ -2 & 0 & 2 \\ -1 & 0 & 1 \end{bmatrix}\) and \(W_{y} = \begin{bmatrix} -1 & -2 & -1 \\ 0 & 0 & 0 \\ 1 & 2 & 1 \end{bmatrix}\), which can be viewed as a combination of the Gaussian filter (to blur the image) and the derivative filter: Wikipedia.
📗 Gradient magnitude at a pixel \((s, t)\) is given by \(G = \sqrt{\nabla_{x}^{2} I\left(s, t\right) + \nabla_{y}^{2} I\left(s, t\right)}\) and gradient direction \(\Theta = arctan\left(\dfrac{\nabla_{y} I\left(s, t\right)}{\nabla_{x} I\left(s, t\right)}\right)\).
Math Note
📗 For HOG features: in every 8 by 8 pixel region of an image, the gradient vectors \(\begin{bmatrix} \nabla_{x} I\left(s, t\right) \\ \nabla_{y} I\left(s, t\right) \end{bmatrix}\) are put into 9 orientation bins, for example, \(\left[0, \dfrac{2}{9} \pi\right], \left[\dfrac{2}{9} \pi, \dfrac{4}{9} \pi\right], ..., \left[\dfrac{16}{9} \pi, 2 \pi\right]\), and the histogram count is used as the HOG features.
📗 The resulting bins are normalized within a block of 2 by 2 regions.
📗 Scale Invariant Feature Transform (SIFT) produces similar feature representation using histogram of oriented gradients: Wikipedia.
➩ It is location invariant.
➩ It is scale invariant: images at different scales are used to compute the features.
➩ It is orientation invariant: dominant orientation in a larger region is calculated and all gradients in the region are rotated by the dominant orientation.
➩ It is illumination and contrast invariant: feature vectors are normalized so that they sum up to 1, and thresholded (values smaller than a threshold, for example 0.2, are made 0).
In-class Discussion
ID:📗 [1 points] Select the pixels in each of the 9 bins. The histogram is computed by summing up the .
1 0
# Haar Features
📗 HOG and SIFT features are too expensive to compute for real-time face detection tasks.
📗 Each image contains large number of locations at different scales, but faces only occur in very few of them.
📗 Each feature and classifier based on the feature should be easy to compute, and boosting can be used to combine simple features and classifiers.
📗 Haar features are differences between sums of pixel intensities in rectangular regions and can be obtained by convolution with filters such as \(\begin{bmatrix} 1 & 1 \\ -1 & -1 \end{bmatrix}\), \(\begin{bmatrix} 1 & -1 \\ 1 & -1 \end{bmatrix}\), ...: Wikipedia.
📗 Integral images (sum of pixel intensities above and to the left of every pixel) can be used to further speed up the computation: Wikipedia.
# Cascade Classifiers
📗 Each weak classifier can be a decision stump (decision tree with only one split) based on a Haar feature.
📗 Finding the threshold by comparing information gain is computationally expensive, so it is usually computed as the mid-point of the averages of the two classes.
📗 A sequence of weak classifiers can be combined into a strong classifier using AdaBoost (Adaptive Boosting).
➩ Start with a weak classifier and equal weights on all training items.
➩ Increase the weights on the items that are classified incorrectly, and train another weak classifier based on the updated weights.
➩ Continue the process to create a sequence of weak classifiers. The combined classifier is called a strong classifier.
📗 A sequence of strong classifiers can be combined into a cascade classifier.
➩ Start with a classifier with close to 100 percent detection rate by a possibly large false-positive rate.
➩ Train the next classifier still with close to 100 percent detection rate but with lower false-positive rate.
➩ Repeat this process to get a sequence of classifiers. The combined classifier called a cascade classifier.
Math Notes
📗 To create each classifier in the cascade classifier:
➩ Start by assigning equal weights for each image: \(w_{i} = \dfrac{1}{n}\) for \(i = 1, 2, ..., n\).
➩ Find optimal feature and threshold given the weights: the cost of mistake on image \(i\) should be weighted by \(w_{i}\), for example, \(C = C_{1} + C_{2} + ... + C_{n}\) where \(C_{i} = w_{i}\) if \(f_{j}\left(x_{i}\right) = y_{i}\) and \(C_{i} = 0\) otherwise.
➩ Choose weight of classifier \(f_{j}\) to be \(\alpha_{j} = \dfrac{1}{2} \log\left(\dfrac{1 - C}{C}\right)\).
➩ Update the weights to \(w_{i} = w_{i} \cdot e^{-y_{i} \alpha_{j} f_{j}\left(x_{i}\right)}\).
➩ Repeat the process until the desired detection rate and false positive rates are reached: the resulting classifier is \(\alpha_{1} f_{1} + \alpha_{2} f_{2} + ...\).
Example

# Viola Jones
📗 Viola Jones algorithm is a popular real-time face detection algorithm: Wikipedia.
➩ Each classifier operates on a 24 by 24 region of the image at multiple scales (scaling factor of 1.25).
➩ The regions can be overlapping. Nearby detection of faces are combined into a single detection.
test fil,cv,hog q
📗 Notes and code adapted from the course taught by Professors Jerry Zhu, Yudong Chen, Yingyu Liang, and Charles Dyer.
📗 Content from note blocks marked "optional" and content from Wikipedia and other demo links are helpful for understanding the materials, but will not be explicitly tested on the exams.
📗 Please use Ctrl+F5 or Shift+F5 or Shift+Command+R or Incognito mode or Private Browsing to refresh the cached JavaScript.
📗 You can expand all TopHat Quizzes and Discussions: , and print the notes: , or download all text areas as text file: .
📗 If there is an issue with TopHat during the lectures, please submit your answers on paper (include your Wisc ID and answers) or this Google form Link at the end of the lecture.
📗 Anonymous feedback can be submitted to: Form. Non-anonymous feedback and questions can be posted on Piazza: Link
Prev: L6, Next: L8
Last Updated: June 27, 2026 at 9:07 PM