Prev: L10, Next: L12
Zoom: Link, Piazza: Link, Google Form: Link.
Wisc ID for in-class quiz: (if your wisc email is "test@wisc.edu", please enter "test")
Token: (will be given during the lectures)
11
id,answer_id;token,answer_check
Slide:
# Natural Language Processing
📗 When processing language data, documents need to be first turned into sequences of word tokens.
➩ Split the string by space and punctuation.
➩ Remove stop-words such as "the", "of", "a", "with".
➩ Lower case all characters.
➩ Stemming or lemmatization words: change "looks", "looked", "looking" to "look".
📗 Each document needs to be converted into a numerical vector for supervised learning tasks.
➩ Bag of words feature uses the number of occurrences of each word type: Wikipedia.
➩ Term-Frequency Inverse-Document-Frequency (TF-IDF) feature adjusts for whether each word type appears in multiple documents: Wikipedia.
# Bag of Words Feature
📗 Given a document \(i \in \left\{1, 2, ..., n\right\}\) and vocabulary with size \(m\), let \(c_{ij}\) be the number of times word \(j \in \left\{1, 2, ..., m\right\}\) appears in the document \(i\), the bag of words representation of document \(i\) is \(x_{i} = \left(x_{i 1}, x_{i 2}, ..., x_{i m}\right)\), where \(x_{ij} = \dfrac{c_{ij}}{c_{i 1} + c_{i 2} + ... + c_{i m}}\).
📗 Sometimes, the features are not normalized, meaning \(x_{ij} = c_{ij}\).
# TF IDF Features
📗 Term frequency is defined the same way as in the bag of words features, \(T F_{ij} = \dfrac{c_{ij}}{c_{i 1} + c_{i 2} + ... + c_{i m}}\).
📗 Inverse document frequency is defined as \(I D F_{j} = \log \left(\dfrac{n}{\left| \left\{i : c_{ij} > 0\right\} \right|}\right)\), where \(\left| \left\{i : c_{ij} > 0\right\} \right|\) is the number of documents that contain word \(j\).
📗 TF IDF representation of document \(i\) is \(x_{i} = \left(x_{i 1}, x_{i 2}, ..., x_{i m}\right)\), where \(x_{ij} = T F_{ij} \cdot I D F_{j}\).
In-class Quiz
📗 [1 points] Given three documents "Guardians of the Galaxy", "Guardians of the Galaxy Vol. 2", "Guardians of the Galaxy Vol. 3", compute the bag of words features and the TF-IDF features of the 3 documents.
| Document | Phrase | Number of times |
| "Guardians of the Galaxy" | "I am Groot" | 13 |
| - | "We are Groot" | 1 |
| "Guardians of the Galaxy Vol. 2" | "I am Groot" | 17 |
| "Guardians of the Galaxy Vol. 3" | "I am Groot" | 13 |
| - | "I love you guys" | 1 |
📗 Answer:
[Q1]
Other students' answers:
# Natural Language Processing Tasks
📗 Supervised learning:
➩ Speech recognition.
➩ Text to speech.
➩ Machine translation.
➩ Image captioning (combines with convolutional networks).
📗 Other similar sequential control or prediction problems:
➩ Handwritting recognition (online recognition: input is a sequence of pen positions, not an image).
➩ Time series prediction (for example, stock price prediction).
➩ Robot control (and other dynamic control tasks).
# Recurrent Networks
📗 Dynamic system uses the idea behind bigram models, and uses the same transition function over time:
➩ \(a_{t+1} = f_{a}\left(a_{t}, x_{t+1}\right)\) and \(y_{t+1} = f_{o}\left(a_{t+1}\right)\)
➩ \(a_{t+2} = f_{a}\left(a_{t+1}, x_{t+2}\right)\) and \(y_{t+2} = f_{o}\left(a_{t+2}\right)\)
➩ \(a_{t+3} = f_{a}\left(a_{t+2}, x_{t+3}\right)\) and \(y_{t+3} = f_{o}\left(a_{t+3}\right)\)
➩ ...
📗 Given input \(x_{i,t,j}\) for item \(i = 1, 2, ..., n\), time \(t = 1, 2, ..., t_{i}\), and feature \(j = 1, 2, ..., m\), the activations can be written as \(a_{t+1} = g\left(w^{\left(a\right)} \cdot a_{t} + w^{\left(x\right)} \cdot x_{t} + b^{\left(a\right)}\right)\).
➩ Each item can be a sequence with different number of elements \(t_{i}\), therefore, each item has different number of activation units \(a_{i,t}\), \(t = 1, 2, ..., t_{i}\).
➩ There can be either one output unit at the end of each item \(o = g\left(w^{\left(o\right)} \cdot a_{t_{i}} + b^{\left(o\right)}\right)\), or \(t_{i}\) output units one for each activation unit \(o_{t} = g\left(w^{\left(o\right)} \cdot a_{t} + b^{\left(o\right)}\right)\).
📗 Multiple recurrent layers can be added where the previous layer activation \(a^{\left(l-1\right)}_{t}\) can be used in place of \(x_{t}\) as the input of the next layer \(a^{\left(l\right)}_{t}\), meaning \(a^{\left(l\right)}_{t+1} = g\left(w^{\left(l\right)} \cdot a^{\left(l\right)}_{t} + w^{\left(l-1\right)} \cdot a^{\left(l-1\right)}_{t+1} + b^{\left(l\right)}\right)\).
📗 Neural networks containing recurrent units are called recurrent neural networks: Wikipedia.
➩ Convolutional layers share weights over different regions of an image.
➩ Recurrent layers share weights over different times (positions in a sequence).
In-class Discussion
📗 [1 points] Which weights (including copies of the same weight) are used in one backpropogation through time gradient descent step when computing \(\dfrac{\partial C}{\partial w^{\left(x\right)}}\)? Use the slider to unfold the network given an input sequence.
Input sequence length: 1
Output is also a sequence:
1 slider
# Backpropogation Through Time
📗 The gradient descent algorithm for recurrent networks are called Backpropagation Through Time (BPTT): Wikipedia.
📗 It computes the gradient by unfolding a recurrent neural network in time.
➩ In the case with one output unit at the end, \(\dfrac{\partial C_{i}}{\partial w^{\left(o\right)}} = \dfrac{\partial C_{i}}{\partial o_{i}} \dfrac{\partial o_{i}}{\partial w^{\left(o\right)}}\), and \(\dfrac{\partial C_{i}}{\partial w^{\left(a\right)}} = \dfrac{\partial C_{i}}{\partial o_{i}} \dfrac{\partial o_{i}}{\partial a_{t_{i}}} \dfrac{\partial a_{t_{i}}}{\partial w^{\left(a\right)}} + \dfrac{\partial C_{i}}{\partial o_{i}} \dfrac{\partial o_{i}}{\partial a_{t_{i}}} \dfrac{\partial a_{t_{i}}}{\partial a_{t_{i} - 1}} \dfrac{\partial a_{t_{i} - 1}}{\partial w^{\left(a\right)}} + ... + \dfrac{\partial C_{i}}{\partial o_{i}} \dfrac{\partial o_{i}}{\partial a_{t_{i}}} \dfrac{\partial a_{t_{i}}}{\partial a_{t_{i} - 1}} ... \dfrac{\partial a_{2}}{\partial a_{1}} \dfrac{\partial a_{1}}{\partial w^{\left(a\right)}}\), and \(\dfrac{\partial C_{i}}{\partial w^{\left(x\right)}} = \dfrac{\partial C_{i}}{\partial o_{i}} \dfrac{\partial o_{i}}{\partial a_{t_{i}}} \dfrac{\partial a_{t_{i}}}{\partial w^{\left(x\right)}} + \dfrac{\partial C_{i}}{\partial o_{i}} \dfrac{\partial o_{i}}{\partial a_{t_{i}}} \dfrac{\partial a_{t_{i}}}{\partial a_{t_{i} - 1}} \dfrac{\partial a_{t_{i} - 1}}{\partial w^{\left(x\right)}} + ... + \dfrac{\partial C_{i}}{\partial o_{i}} \dfrac{\partial o_{i}}{\partial a_{t_{i}}} \dfrac{\partial a_{t_{i}}}{\partial a_{t_{i} - 1}} ... \dfrac{\partial a_{2}}{\partial a_{1}} \dfrac{\partial a_{1}}{\partial w^{\left(x\right)}}\).
➩ The case with one output unit for each activation unit is similar.
In-class Discussion
📗 [1 points] Which weights (including copies of the same weight) are used in one backpropogation through time gradient descent step when computing \(\dfrac{\partial C}{\partial w^{\left(x\right)}}\)? Use the slider to unfold the network given an input sequence.
Input sequence length: 1
Output is also a sequence:
1 slider
# Vanishing and Exploding Gradient
📗 Vanishing gradient: if the weights are small, the gradient through many layers will shrink exponentially to \(0\).
📗 Exploding gradient: if the weights are large, the gradient through many layers will grow exponentially to \(\pm \infty\).
📗 In recurrent neural networks, if the sequences are long, the gradients can easily vanish or explode.
📗 In deep fully connected or convolutional networks, vanishing or exploding gradient is also a problem.
# Gated Recurrent Unit and Long Short Term Memory
📗 Gated hidden units can be added to keep track of memories: Link.
➩ Technically adding small weights will not lead to vanishing gradient like multiplying small weights, so hidden units can be added together.
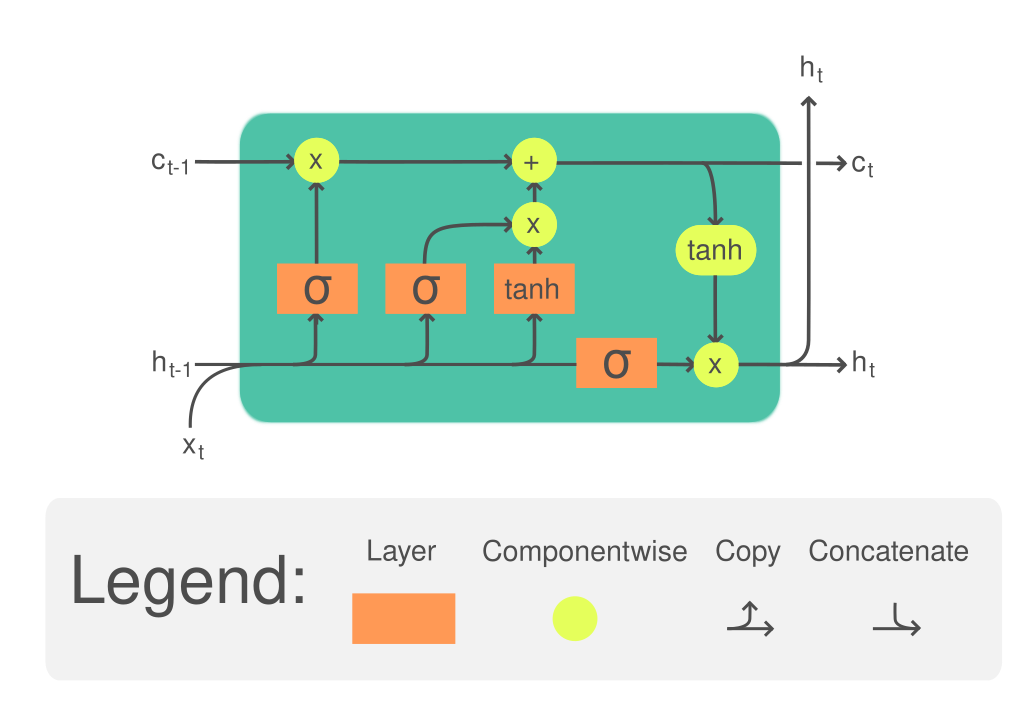
📗 Long Short Term Memory (LSTM): Wikipedia.
➩ The (long term) memory is updated by \(a^{\left(c\right)}_{t} = a^{\left(f\right)}_{t} \times a^{\left(c\right)}_{t-1} + a^{\left(i\right)}_{t} \times a^{\left(g\right)}_{t}\), where \(a^{\left(c\right)}\) is called the cell unit, \(a^{\left(f\right)}\) is the forget gate and controls how much memory to forget, \(a^{\left(i\right)}\) is the input gate and controls how much information to add to memory, \(a^{\left(g\right)}\) is the new values added to memory.
➩ The (short term memory) state is updated by \(a^{\left(h\right)} = a^{\left(o\right)} \times g\left(a^{\left(c\right)}_{t}\right)\), where \(a^{\left(h\right)}\) is the usual recurrent unit called hidden state, \(a^{\left(o\right)}\) is the output gate and controls how much information from the memory to reflect in the next state.
➩ Each of the gates are computed based on the hidden state and the input features (or the previous layer hidden states if there are multiple LSTM layers): \(a^{\left(f\right)}_{t} = g\left(w^{\left(f\right)} \cdot x_{t} + w^{\left(F\right)} \cdot a^{\left(h\right)}_{t-1} + b^{\left(f\right)}\right)\), \(a^{\left(i\right)}_{t} = g\left(w^{\left(i\right)} \cdot x_{t} + w^{\left(I\right)} \cdot a^{\left(h\right)}_{t-1} + b^{\left(i\right)}\right)\), \(a^{\left(g\right)}_{t} = g\left(w^{\left(g\right)} \cdot x_{t} + w^{\left(G\right)} \cdot a^{\left(h\right)}_{t-1} + b^{\left(g\right)}\right)\), \(a^{\left(o\right)}_{t} = g\left(w^{\left(o\right)} \cdot x_{t} + w^{\left(O\right)} \cdot a^{\left(h\right)}_{t-1} + b^{\left(o\right)}\right)\).
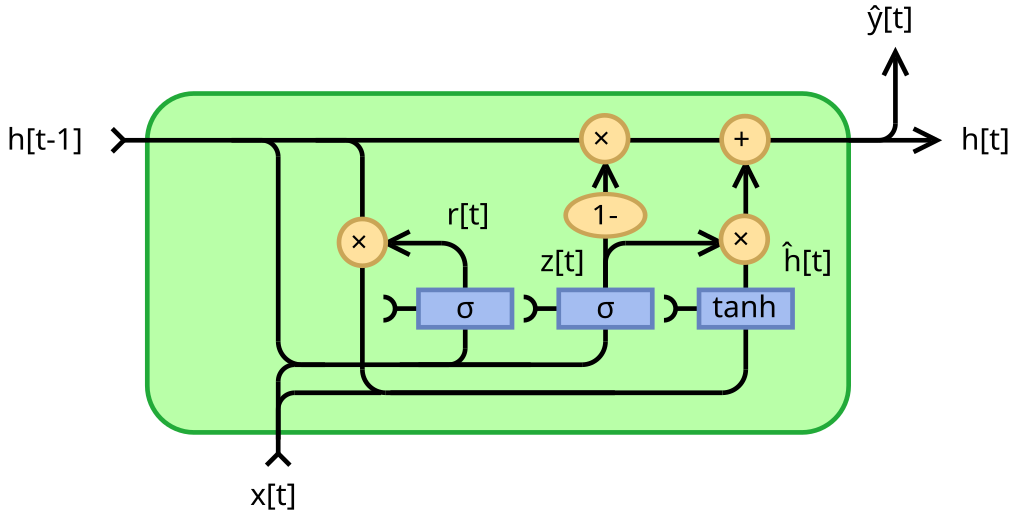
📗 Gated Recurrent Unit (GRU): Wikipedia.
➩ The memory is also updated through addition: \(a^{\left(h\right)}_{t} = \left(1 - a^{\left(z\right)}_{t}\right) \times a^{\left(h\right)}_{t-1} + a^{\left(z\right)}_{t} \times a^{\left(g\right)}_{t}\), where \(a^{\left(z\right)}\) is the update gate, and \(a^{\left(r\right)}\) is the reset gate.
➩ Each of the gates are computed in a similar way: \(a^{\left(z\right)}_{t} = g\left(w^{\left(z\right)} \cdot x_{t} + w^{\left(Z\right)} \cdot a^{\left(h\right)}_{t-1} + b^{\left(z\right)}\right)\), \(a^{\left(r\right)}_{t} = g\left(w^{\left(r\right)} \cdot x_{t} + w^{\left(R\right)} \cdot a^{\left(h\right)}_{t-1} + b^{\left(r\right)}\right)\), \(a^{\left(g\right)}_{t} = g\left(w^{\left(g\right)} \cdot x_{t} + w^{\left(G\right)} \cdot a^{\left(r\right)}_{t} \times a^{\left(h\right)}_{t-1} + b^{\left(g\right)}\right)\).
Example
📗 GRU:
📗 LTSM:
# Questions?
📗 If you have questions, please use (i) Zoom chat, (ii) Piazza: Link, (iii) Office hours and discussion sessions. Please do NOT use Canvas mail and use email only to the course instructor (not TAs) for grading issues.
Additional In-class Discussion
📗 Sometimes a question not in the notes will be asked during the lecture, you can submit your answer here:
Notes (not visible to other students):
[Q4]
Submit your answer to see other students answers (click the submit button to refresh):
Additional In-class Quiz
📗 Sometimes a question not in the notes will be asked during the lecture, you can submit your answer here:
A. B.
C.
D.
E.
Notes (not visible to other students):
[Q5]
Submit your answer to see other students answers (click the submit button to refresh):
test bt,rnn,bpt q https://script.google.com/macros/s/AKfycbyiidUAdiLc3YrKgOAM6T95ATulwDQxQilWVv1bK1L5sKRl8ozXfVs4PjCC2VtMWcIBpg/exec
# In-class Quiz Instructions
📗 To get full points on the in-class quizzes for a lecture:
➩ Submit relevant answers to the questions discussed during the lecture: incorrect answers are okay.
➩ Some questions require [notes] to earn the point.
➩ Some questions require special ID (given during the lecture) to earn the point.
➩ Do not submit answers to questions that are not discussed during the lectures. Each such submission will result in a deduction of one point.
➩ Submissions after the lecture, before the midterm (first 14 lectures) and the final exam (last 14 lectures), are accepted. After the exams, no in-class quiz submissions will be accepted.
➩ The grade on Canvas Assignment Q11 is computed as number of points divided by the number of questions asked (out of 1) and updated on Canvas every weekend.
📗 If there are any issues with submission on the website, please use this Google form: Link.
📗 Bonus point opportunities during a few lectures (added to in-class quiz above 20 points).
📗 Notes and code adapted from the course taught by Professors Jerry Zhu, Blerina Gkotse, Yudong Chen, Yingyu Liang, Charles Dyer. Some content are generated using Copilot .
Prev: L10, Next: L12
Last Updated: July 23, 2026 at 2:02 AM