Prev: L11, Next: L13
Zoom: Link, Piazza: Link, Google Form: Link.
Wisc ID for in-class quiz: (if your wisc email is "test@wisc.edu", please enter "test")
Token: (will be given during the lectures)
12
id,answer_id;token,answer_check
Slide:
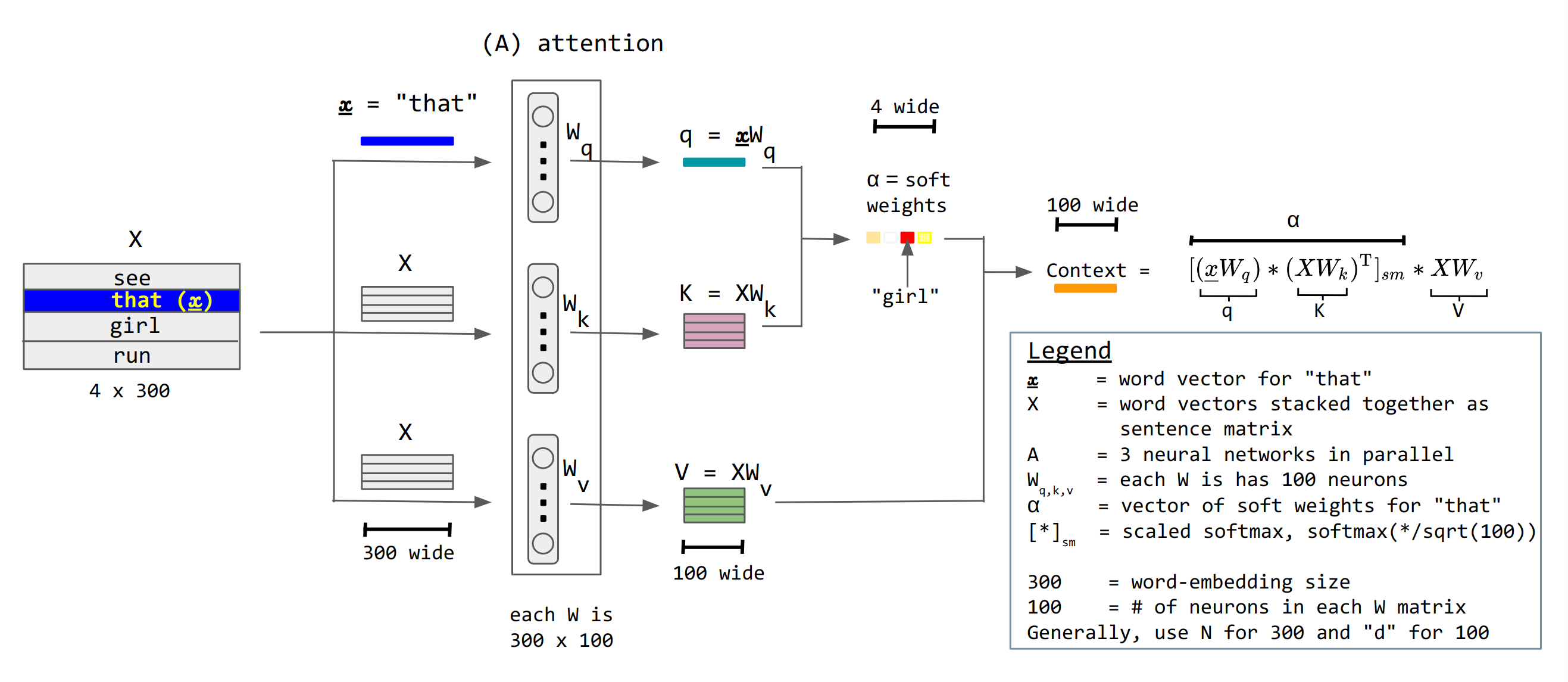
# Attention Mechanism
📗 Attention units keep track of which parts of the sentence is important and pay attention to, for example, scaled dot product attention units: Wikipedia.
➩ \(a^{\left(h\right)}_{t} = g\left(w^{\left(x\right)} \cdot x_{t} + b^{\left(x\right)}\right)\) is not recurrent.
➩ There are value units \(a^{\left(v\right)}_{t} = w^{\left(v\right)} \cdot a^{\left(h\right)}_{t}\), key units \(a^{\left(k\right)}_{t} = w^{\left(k\right)} \cdot a^{\left(h\right)}_{t}\), and query units \(a^{\left(q\right)}_{t} = w^{\left(q\right)} \cdot a^{\left(h\right)}_{t}\), and attention context can be computed as \(g\left(\dfrac{a^{\left(q\right)}_{s} \cdot a^{\left(k\right)}_{t}}{\sqrt{m}}\right) \cdot a^{\left(v\right)}_{t}\) where \(g\) is the softmax activation: here \(a^{\left(q\right)}_{s}\) represents the first word, \(a^{\left(k\right)}_{t}\) represents the second word, \(a^{\left(q\right)}_{s} \cdot a^{\left(k\right)}_{t}\) is the dot product (which represents the cosine of the angle between the two words, i.e. how similar or related the two words are), and \(a^{\left(v\right)}_{t}\) is the value of the second word to send to the next layer.
➩ The attention matrix is usually masked so that a unit \(a_{t}\) cannot pay attention to another unit in the future \(a_{t+1}, a_{t+2}, a_{t+3}, ...\) by making the \(a^{\left(q\right)}_{s} \cdot a^{\left(k\right)}_{t} = -\infty\) when \(s \geq t\) so that \(e^{a^{\left(q\right)}_{s} \cdot a^{\left(k\right)}_{t}} = 0\) when \(s \geq t\).
➩ There can be multiple parallel attention units called multi-head attention.
In-class Quiz
ID:📗 [1 points] Compute the attention weights and the context value of the word with \(q_{i} = x_{i} \cdot w_{q}\) = ?
| Words | Key \(k_{j} = x_{j} \cdot w_{k}\) | Value \(v_{j} = x_{j} \cdot w_{v}\) | Attention Weights \(\alpha\) |
📗 Answer: .
[Q1]
In-class Quiz
ID:📗 [4 points] Compute the context value of the word with \(q_{i} = x_{i} \cdot w_{q}\) = . You can enter the scaled dot products (optional) in the table and use the "Softmax" button to compute the soft attention weights.
| Words | Key \(k_{j} = x_{j} \cdot w_{k}\) | Value \(v_{j} = x_{j} \cdot w_{v}\) | Attention Weights \(\alpha\) |
| : | |||
| : | |||
| : | |||
| : |
📗 Answer: .
[Q2]
# Transformers
📗 Transformer is a neural network with attention mechanism and without reccurent units: Wikipedia.
📗 A transformer layer:
➩ Attention mechanism (multi-head attention).
➩ Feed-forward network.
➩ Residual connections.
📗 Tokenizer: convert between words and token IDs (integers), Link.
📗 Word embeddings: low dimensional vector representation of individual words (tokens).
➩ Word2vec: Wikipedia.
➩ Universal sentence encoder: Link.
📗 Positional encoding are used so that embedding vectors contain information about the word token and its position.
➩ Trained weights, or,
➩ Calculated by \(P\left(k, 2 i\right) = \sin\left(\dfrac{k}{n^{2 i / d}}\right)\) and \(P\left(k, 2 i + 1\right) = \cos\left(\dfrac{k}{n^{2 i / d}}\right)\) for word token \(k\) to position \(j \in \left\{2 i, 2 i + 1\right\}\) in the embedding vector: Link.
📗 Composite encoding = word embeddings + position embeddings.
➩ Attention mechanism produces contextual embeddings.
📗 Layer normalization trick is used so that means and variances of the units between attention layers and fully connected layers stay the same.
➩ Input \(a_{i}\), compute \(\mu_{x} = \dfrac{1}{d} \displaystyle\sum_{i=1}^{d} x_{i}\) and \(\sigma^{2}_{x} = \dfrac{1}{d} \displaystyle\sum_{i=1}^{d} \left(x_{i} - \mu_{x}\right)^{2}\).
➩ Output \(a^{\left(n\right)}_{i} = \dfrac{a_{i} - \mu_{x}}{\sqrt{\sigma^{2}_{x} + \varepsilon}}\), added \(\varepsilon\) small to prevent \(\sigma\) close to 0.
📗 Encoder-Decoder structure:
➩ Encoder: input sequence to a continuous representation \(z\) (useful for classification).
➩ Decoder: from \(z\), generate output sequence (useful for generation).
Example
From "Attention is All You Need":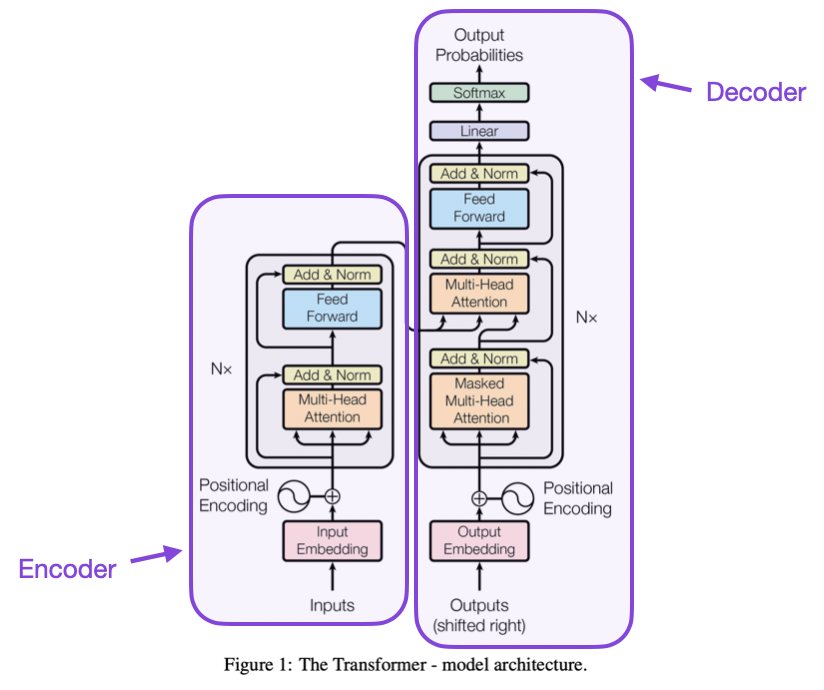
# Large Language Models
📗 GPT Series (Generative Pre-trained Transformer): Wikipedia.
➩ Pre-training: train all the weights on general purpose text dataset to learn contextualized word and sentence representations.
➩ Fine tuning for pre-trained decoder models freezes a subset of the weights (usually in earlier layers) and updates the other weights (usually the later layers) based on new datasets: Wikipedia.
📗 BERT (Bidirectional Encoder Representations from Transformers): Wikipedia.
➩ Fine tuning for pre-training encoder models adds task heads (additional layers at the end) and trains the weights in the task heads (sometimes also updates the pre-trained weights) for specific tasks.
📗 Many other large language models developed by different companies: Link.
➩ Prompt engineering does not alter the weights, and only provides more context (in the form of examples): Link, Wikipedia.
➩ Reinforcement learning from human feedback (RLHF) uses reinforcement learning techniques to update the model based on human feedback (in the form of rewards, and the model optimizes the reward instead of some form of costs): Wikipedia.
# Relationships in Data
📗 There can be relationships between points (items) in the data.
➩ Social networks: individuals related by friendship.
➩ Biology and chemistry: bonds between compounds or molecules.
➩ Citation networks: scientific paper cite each other.
📗 In the citation example: citations are not features, they are links (edges in the input graph).
➩ Features: title, abstract, authors.
➩ Labels: math, science, engineering.
➩ More signal from the relationships: cite each other, more likely from the same field.
# Graph Neural Networks
➩ Images can be viewed as graphs where pixels are nodes and neighboring pixels are connected by edges.
📗 An example of a graph convolution layer is given by: \(a^{\left(l + 1\right)} = g\left(A_{G} w^{\left(l\right)} \cdot a^{\left(l\right)} + b^{\left(l\right)}\right)\) for the graph \(G\) with adjacency matrix with self loops added (add an edge from every node to itself) \(A\) and the corresponding degree matrix \(D\).
➩ An example of \(A_{G} = D^{- \dfrac{1}{2}} A D^{- \dfrac{1}{2}}\).
📗 Pooling layers can be local or global.
➩ Local: downsampling, for example, k-nearest neighbor pooling, top-k pooling.
➩ Global: permutation invariant, for example, sum, mean, maximum.
📗 Comparison between CNN, RNN, GNN:
➩ CNN share weights over space (regions of pixels).
➩ RNN share weights over time (sequences of tokens).
➩ GNN share weights over graph neighborhoods (links or edges in the graph).
# Questions?
📗 If you have questions, please use (i) Zoom chat, (ii) Piazza: Link, (iii) Office hours and discussion sessions. Please do NOT use Canvas mail and use email only to the course instructor (not TAs) for grading issues.
Additional In-class Discussion
📗 Sometimes a question not in the notes will be asked during the lecture, you can submit your answer here:
Notes (not visible to other students):
[Q3]
Submit your answer to see other students answers (click the submit button to refresh):
Additional In-class Quiz
📗 Sometimes a question not in the notes will be asked during the lecture, you can submit your answer here:
A. B.
C.
D.
E.
Notes (not visible to other students):
[Q4]
Submit your answer to see other students answers (click the submit button to refresh):
test ato,att q https://script.google.com/macros/s/AKfycbyiidUAdiLc3YrKgOAM6T95ATulwDQxQilWVv1bK1L5sKRl8ozXfVs4PjCC2VtMWcIBpg/exec
# In-class Quiz Instructions
📗 To get full points on the in-class quizzes for a lecture:
➩ Submit relevant answers to the questions discussed during the lecture: incorrect answers are okay.
➩ Some questions require [notes] to earn the point.
➩ Some questions require special ID (given during the lecture) to earn the point.
➩ Do not submit answers to questions that are not discussed during the lectures. Each such submission will result in a deduction of one point.
➩ Submissions after the lecture, before the midterm (first 14 lectures) and the final exam (last 14 lectures), are accepted. After the exams, no in-class quiz submissions will be accepted.
➩ The grade on Canvas Assignment Q12 is computed as number of points divided by the number of questions asked (out of 1) and updated on Canvas every weekend.
📗 If there are any issues with submission on the website, please use this Google form: Link.
📗 Bonus point opportunities during a few lectures (added to in-class quiz above 20 points).
📗 Notes and code adapted from the course taught by Professors Jerry Zhu, Blerina Gkotse, Yudong Chen, Yingyu Liang, Charles Dyer. Some content are generated using Copilot .
Prev: L11, Next: L13
Last Updated: July 19, 2026 at 1:41 PM