Prev: L13, Next: L15
Course Links: Canvas, Piazza, TopHat (212925)
Zoom Links: MW 4:00, TR 1:00, TR 2:30.
Tools
📗 You can expand all TopHat Quizzes and Discussions: , and print the notes: , or download all text areas as text file: .
📗 For visibility, you can resize all diagrams on page to have a maximum height that is percent of the screen height: .
📗 Calculator:
📗 Canvas:
pen
# Attention Mechanism
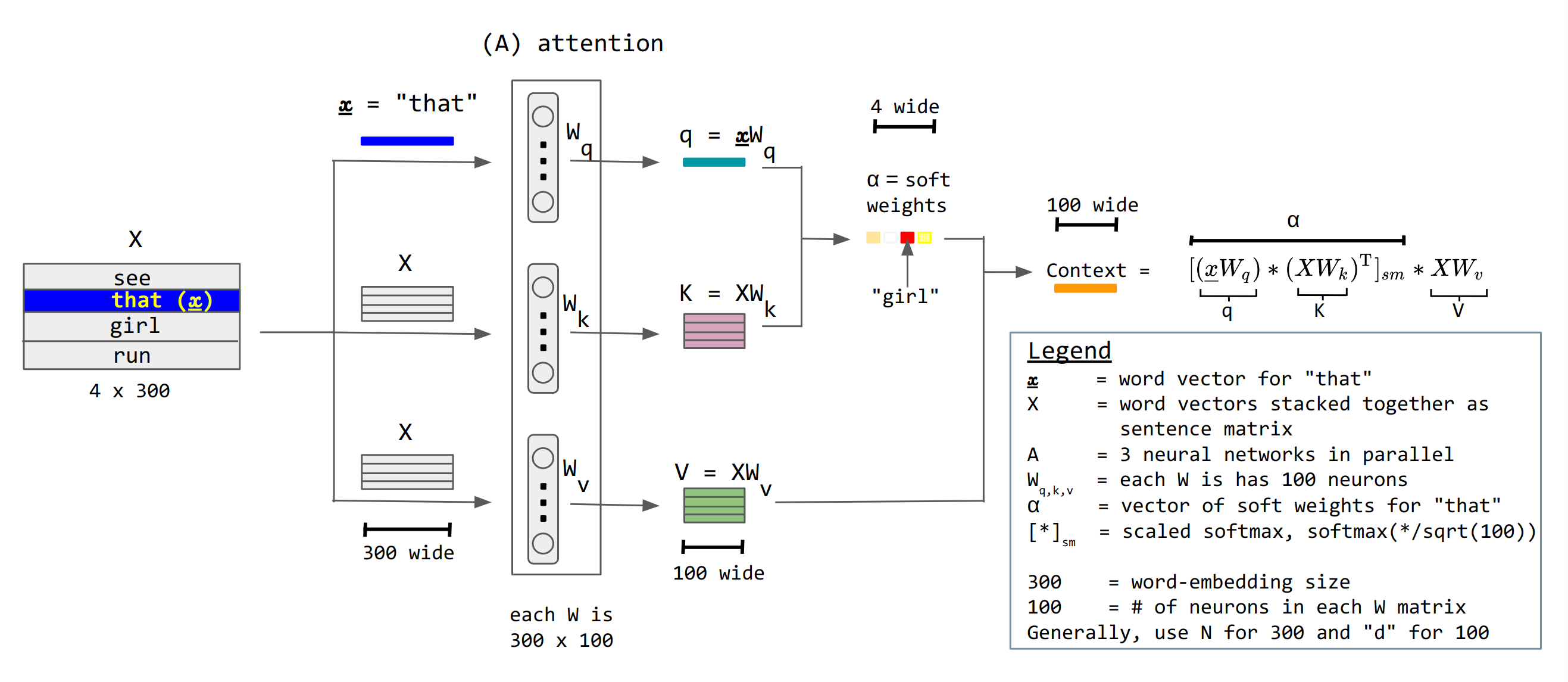
📗 Attention units keep track of which parts of the sentence is important and pay attention to, for example, scaled dot product attention units: Wikipedia.
➩ \(a^{\left(h\right)}_{t} = g\left(w^{\left(x\right)} \cdot x_{t} + b^{\left(x\right)}\right)\) is not recurrent.
➩ There are value units \(a^{\left(v\right)}_{t} = w^{\left(v\right)} \cdot a^{\left(h\right)}_{t}\), key units \(a^{\left(k\right)}_{t} = w^{\left(k\right)} \cdot a^{\left(h\right)}_{t}\), and query units \(a^{\left(q\right)}_{t} = w^{\left(q\right)} \cdot a^{\left(h\right)}_{t}\), and attention context can be computed as \(g\left(\dfrac{a^{\left(q\right)}_{s} \cdot a^{\left(k\right)}_{t}}{\sqrt{m}}\right) \cdot a^{\left(v\right)}_{t}\) where \(g\) is the softmax activation: here \(a^{\left(q\right)}_{s}\) represents the first word, \(a^{\left(k\right)}_{t}\) represents the second word, \(a^{\left(q\right)}_{s} \cdot a^{\left(k\right)}_{t}\) is the dot product (which represents the cosine of the angle between the two words, i.e. how similar or related the two words are), and \(a^{\left(v\right)}_{t}\) is the value of the second word to send to the next layer.
➩ The attention matrix is usually masked so that a unit \(a_{t}\) cannot pay attention to another unit in the future \(a_{t+1}, a_{t+2}, a_{t+3}, ...\) by making the \(a^{\left(q\right)}_{s} \cdot a^{\left(k\right)}_{t} = -\infty\) when \(s \geq t\) so that \(e^{a^{\left(q\right)}_{s} \cdot a^{\left(k\right)}_{t}} = 0\) when \(s \geq t\).
➩ There can be multiple parallel attention units called multi-head attention.
In-class Quiz
(Past Exam Question) ID:📗 [1 points] Compute the attention weights and the context value of the word with \(q_{i} = x_{i} \cdot w_{q}\) = ?
| Words | Key \(k_{j} = x_{j} \cdot w_{k}\) | Value \(v_{j} = x_{j} \cdot w_{v}\) | Attention Weights \(\alpha\) |
📗 Answer: .
In-class Quiz
(Past Exam Question) ID:📗 [1 points] Compute the attention weights and the context value of the word with \(q_{i} = x_{i} \cdot w_{q}\) = ?
| Words | Key \(k_{j} = x_{j} \cdot w_{k}\) | Value \(v_{j} = x_{j} \cdot w_{v}\) | Attention Weights \(\alpha\) |
| : | |||
| : | |||
| : | |||
| : |
📗 Answer: .
# Transformers
📗 Transformer is a neural network with attention mechanism and without reccurent units: Wikipedia.
📗 A transformer layer:
➩ Attention mechanism (multi-head attention).
➩ Feed-forward network.
➩ Residual connections.
📗 Tokenizer: convert between words and token IDs (integers), Link.
📗 Word embeddings: low dimensional vector representation of individual words (tokens).
➩ Word2vec: Wikipedia.
➩ Universal sentence encoder: Link.
📗 Positional encoding are used so that embedding vectors contain information about the word token and its position.
➩ Trained weights, or,
➩ Calculated by \(P\left(k, 2 i\right) = \sin\left(\dfrac{k}{n^{2 i / d}}\right)\) and \(P\left(k, 2 i + 1\right) = \cos\left(\dfrac{k}{n^{2 i / d}}\right)\) for word token \(k\) to position \(j \in \left\{2 i, 2 i + 1\right\}\) in the embedding vector: Link.
📗 Composite encoding = word embeddings + position embeddings.
➩ Attention mechanism produces contextual embeddings.
📗 Layer normalization trick is used so that means and variances of the units between attention layers and fully connected layers stay the same.
➩ Input \(a_{i}\), compute \(\mu_{x} = \dfrac{1}{d} \displaystyle\sum_{i=1}^{d} x_{i}\) and \(\sigma^{2}_{x} = \dfrac{1}{d} \displaystyle\sum_{i=1}^{d} \left(x_{i} - \mu_{x}\right)^{2}\).
➩ Output \(a^{\left(n\right)}_{i} = \dfrac{a_{i} - \mu_{x}}{\sqrt{\sigma^{2}_{x} + \varepsilon}}\), added \(\varepsilon\) small to prevent \(\sigma\) close to 0.
📗 Encoder-Decoder structure:
➩ Encoder: input sequence to a continuous representation \(z\) (useful for classification).
➩ Decoder: from \(z\), generate output sequence (useful for generation).
Example
From "Attention is All You Need":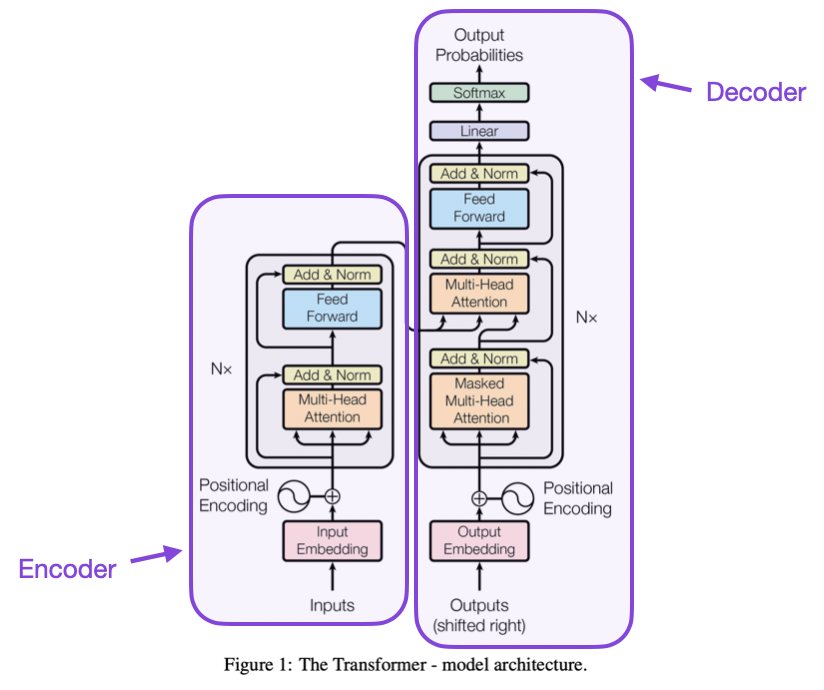
# Large Language Models
📗 GPT Series (Generative Pre-trained Transformer): Wikipedia.
➩ Pre-training: train all the weights on general purpose text dataset to learn contextualized word and sentence representations.
➩ Fine tuning for pre-trained decoder models freezes a subset of the weights (usually in earlier layers) and updates the other weights (usually the later layers) based on new datasets: Wikipedia.
📗 BERT (Bidirectional Encoder Representations from Transformers): Wikipedia.
➩ Fine tuning for pre-training encoder models adds task heads (additional layers at the end) and trains the weights in the task heads (sometimes also updates the pre-trained weights) for specific tasks.
📗 Many other large language models developed by different companies: Link.
➩ Prompt engineering does not alter the weights, and only provides more context (in the form of examples): Link, Wikipedia.
➩ Reinforcement learning from human feedback (RLHF) uses reinforcement learning techniques to update the model based on human feedback (in the form of rewards, and the model optimizes the reward instead of some form of costs): Wikipedia.
test ato,att q
📗 Notes and code adapted from the course taught by Professors Jerry Zhu, Yingyu Liang, and Charles Dyer.
📗 Content from note blocks marked "optional" and content from Wikipedia and other demo links are helpful for understanding the materials, but will not be explicitly tested on the exams.
📗 Please use Ctrl+F5 or Shift+F5 or Shift+Command+R or Incognito mode or Private Browsing to refresh the cached JavaScript.
📗 You can expand all TopHat Quizzes and Discussions: , and print the notes: , or download all text areas as text file: .
📗 If there is an issue with TopHat during the lectures, please submit your answers on paper (include your Wisc ID and answers) or this Google form Link at the end of the lecture.
📗 Anonymous feedback can be submitted to: Form.
Prev: L13, Next: L15
Last Updated: June 27, 2026 at 9:06 PM