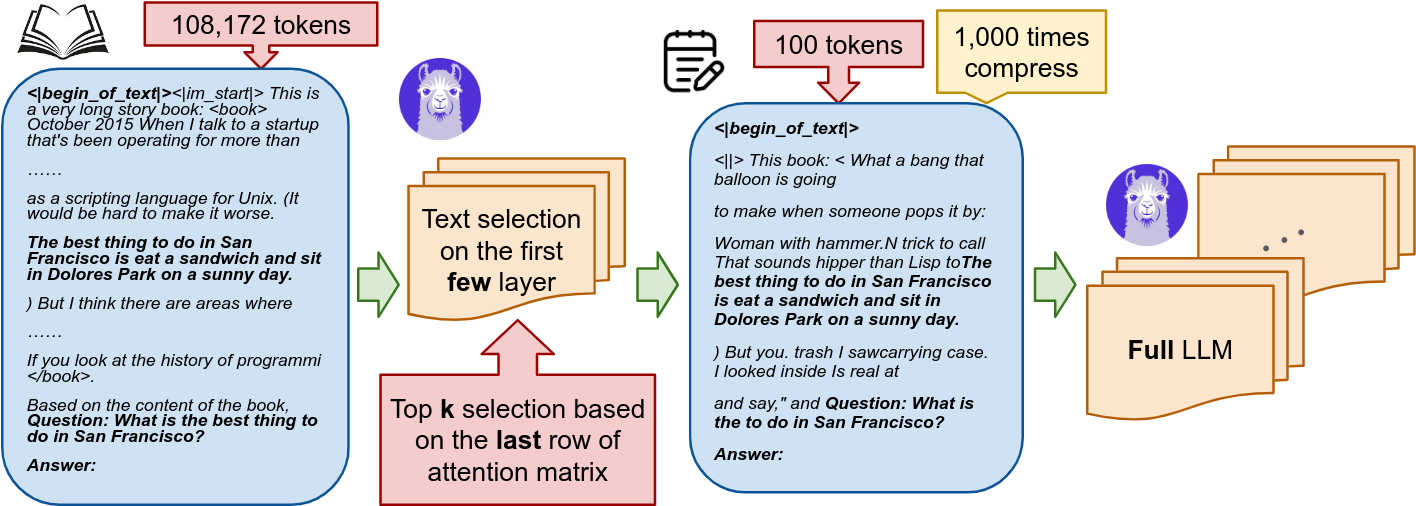
Discovering the Gems in Early Layers: Accelerating Long-Context LLMs with 1000x Input Token Reduction
ACL 2026 Findings

I am a Member of Technical Staff at SpaceXAI on the coding specialist team — the core post-training coding team for Grok 4.5. With five teammates, our scope covers webdev, terminal use, kernel, infra, CUA, MLE specialist training, and full-stack long-horizon agentic training. I previously worked on pretraining and agentic search, and have contributed to Grok 4.1, Grok 4.2, Grok 4.3, and Grok 4.5, as well as Grok Build 0.1.
Previously, I was a Senior Research Scientist at MongoDB + Voyage AI, working with Tengyu Ma. I received my Ph.D. in Computer Sciences from the University of Wisconsin–Madison in 2024, advised by Yingyu Liang, and my B.S. in Computer Science and Pure Mathematics Advanced from HKUST in 2019.
Full publication list, awards, and earlier roles are in my CV and PhD thesis.
ACL 2026 Findings

NeurIPS 2025
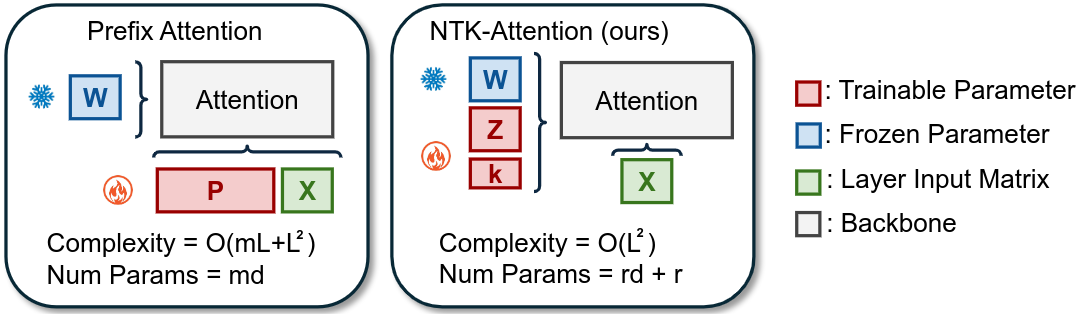
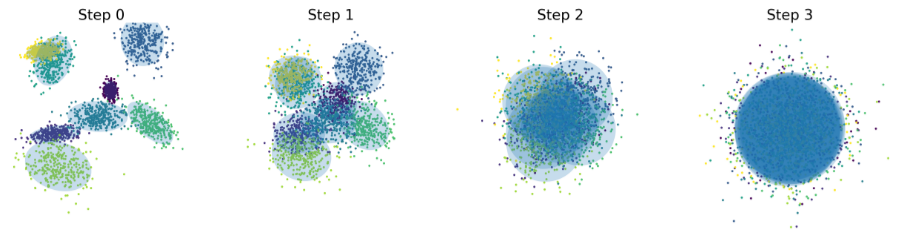
ICCV 2025
ICML 2025
ICML 2025
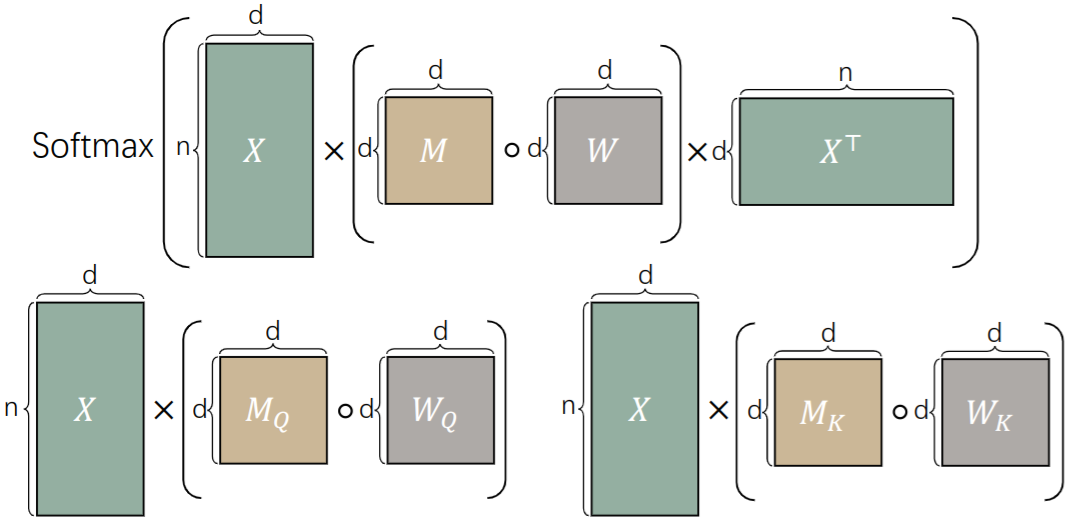
ICLR 2025
AIStats 2025
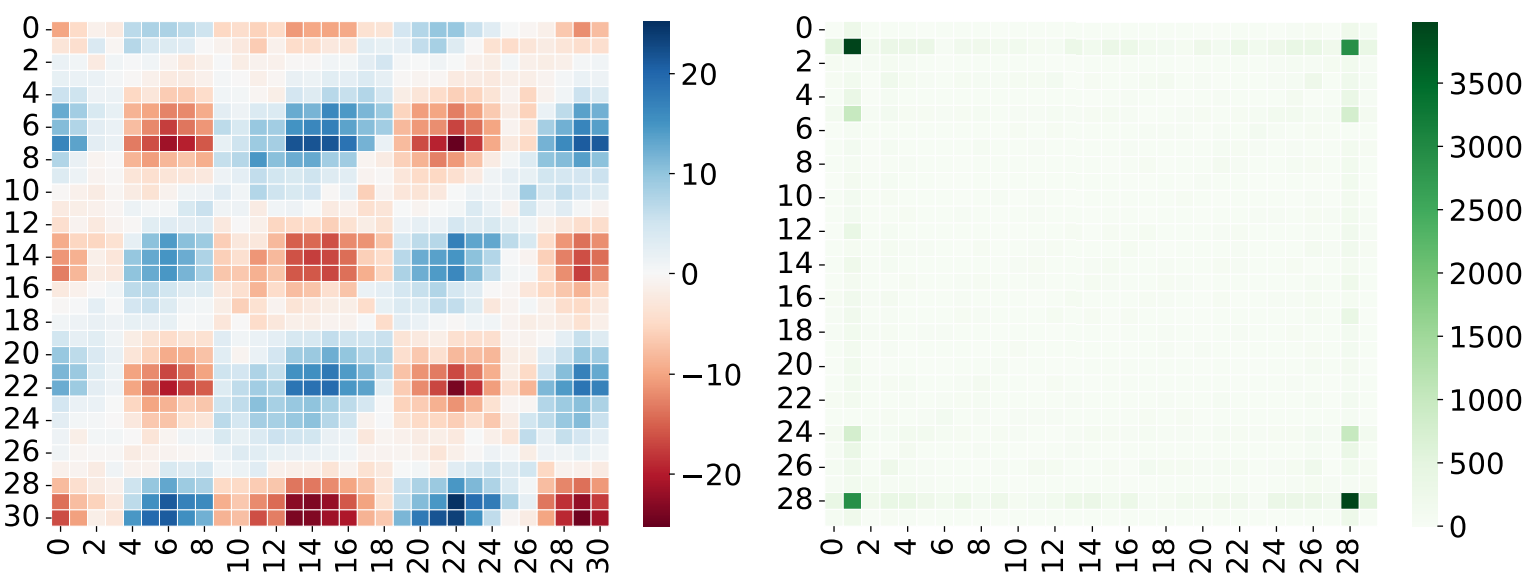
AIStats 2025
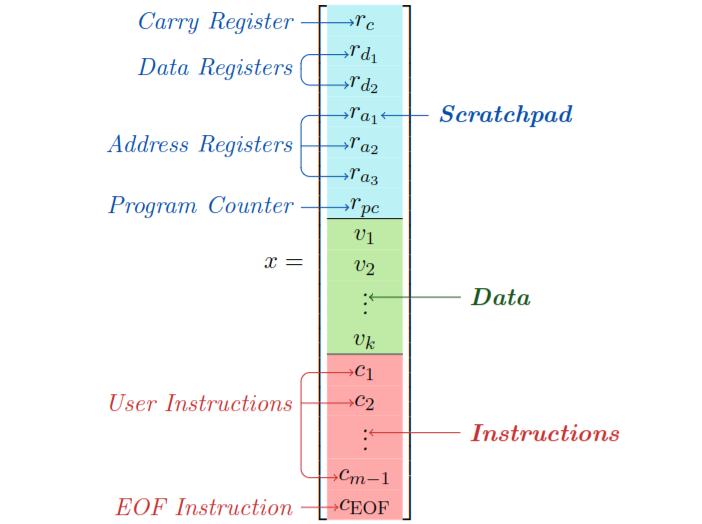
AIStats 2025
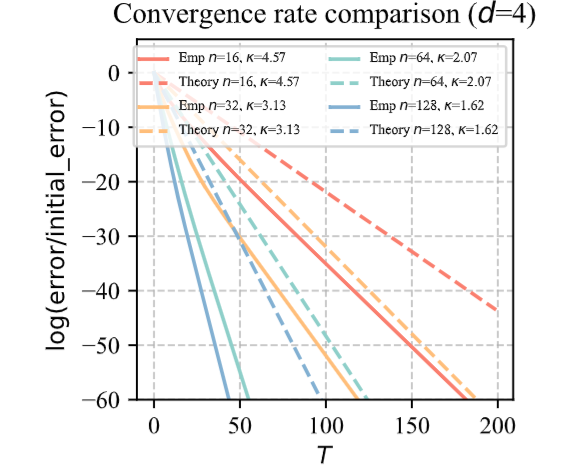
AIStats 2025
CPAL 2025 Oral
CPAL 2025 Oral
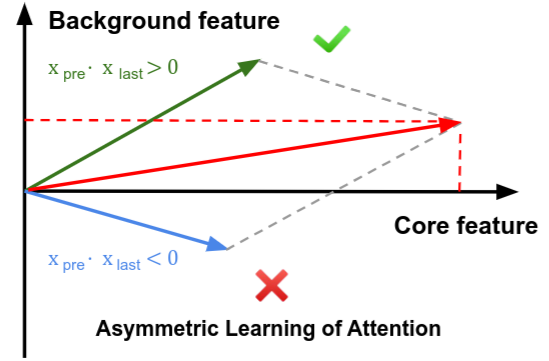
CPAL 2025

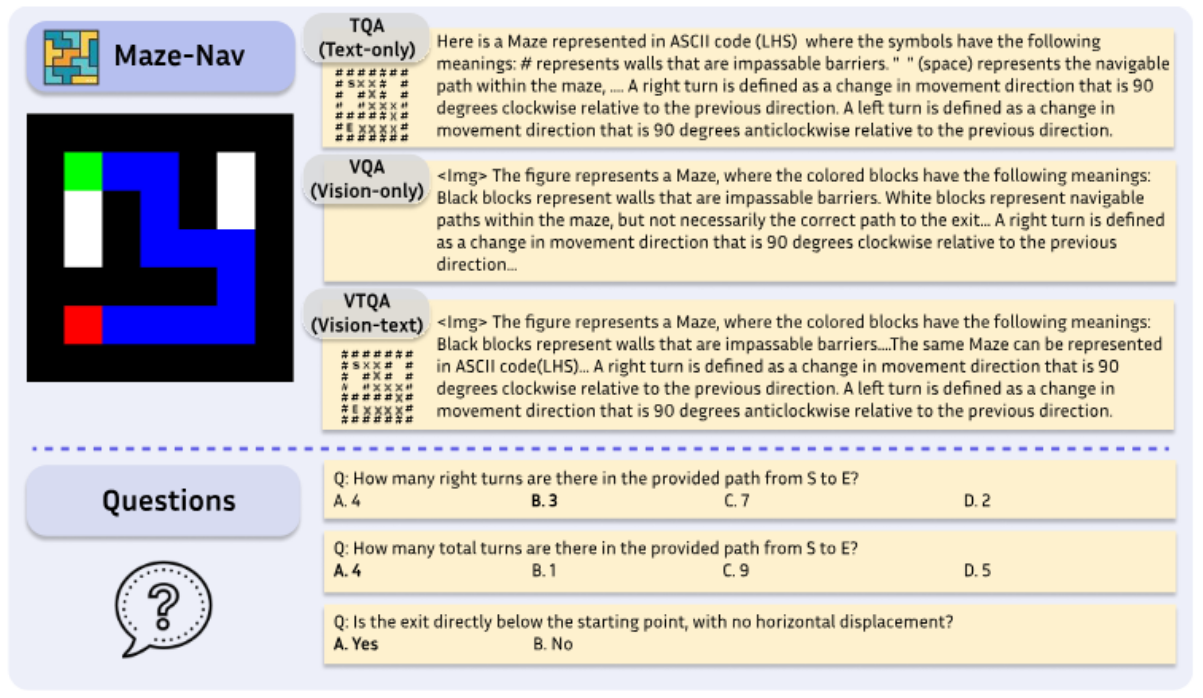
NeurIPS 2024
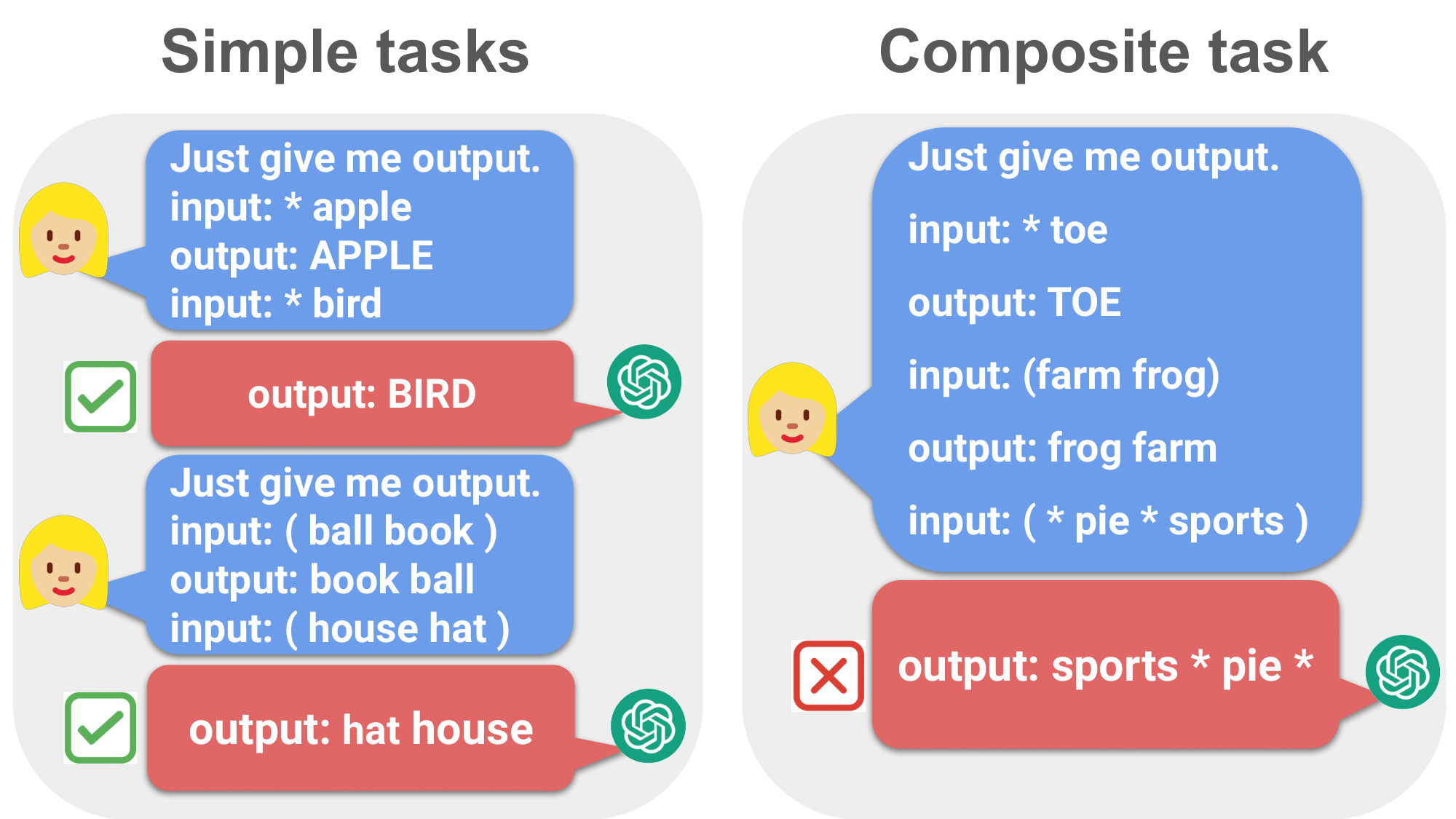
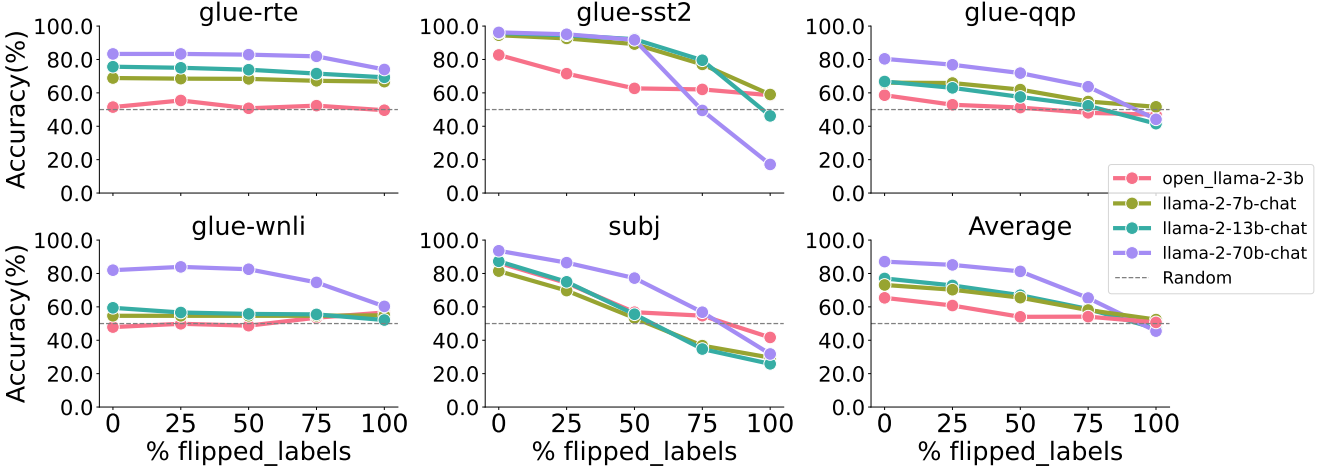
ICML 2024
ICLR 2024

CPAL 2024 Oral
NeurIPS 2023
NeurIPS 2023 Spotlight
ICML 2023
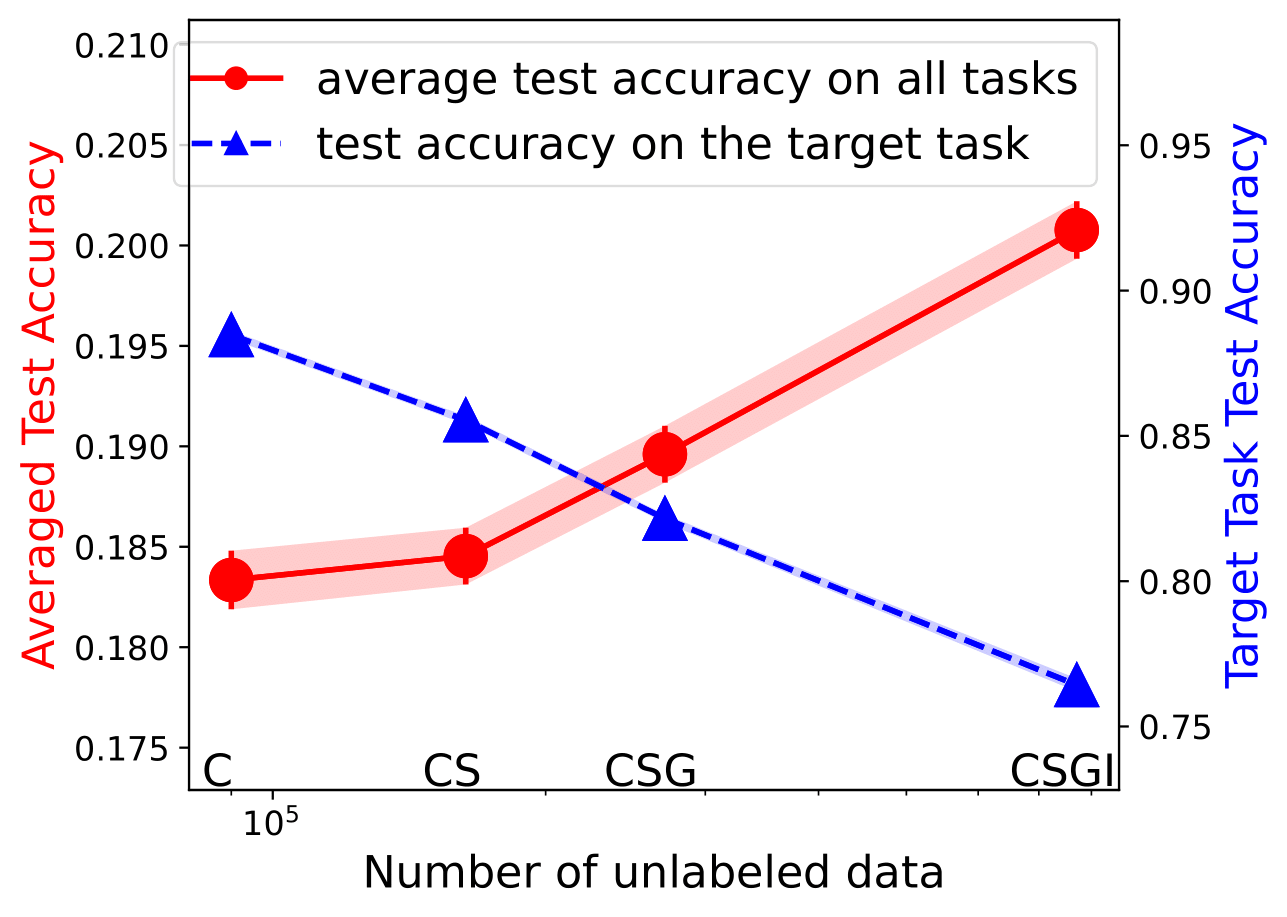
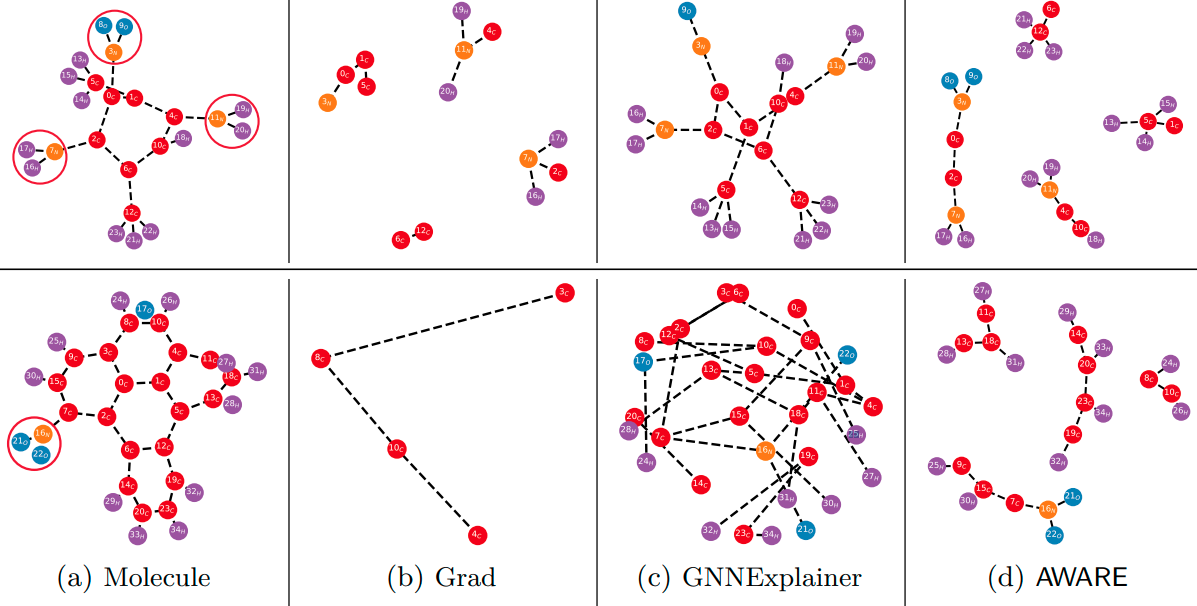
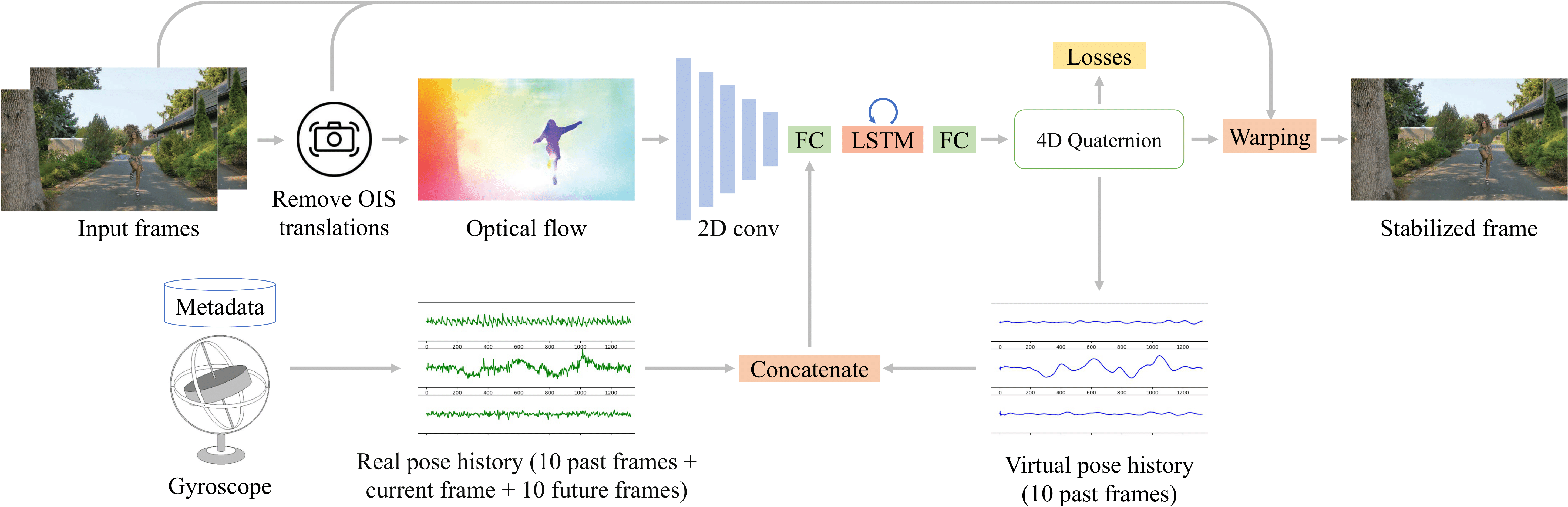
ICLR 2023 Spotlight (Accept Rate: 7.95%)


Coding specialist team for Grok 4.5 — webdev, terminal use, kernel, infra, CUA, MLE specialist training, and full-stack long-horizon agentic training; previously pretraining and agentic search. Contributed to Grok 4.1, Grok 4.2, Grok 4.3, and Grok 4.5, as well as Grok Build 0.1.

Embedding & reranking; led rerank-2.5 end-to-end training.


Long-context LLMs, in-context learning, and inference acceleration.




Conference reviewer: ICLR 2022–2026, NeurIPS 2022–2025, ICML 2022 & 2024–2026, COLM 2025, AISTATS 2025–2026, AAAI 2026, IJCAI 2025, CVPR 2021–2022 & 2025–2026, ICCV 2021–2025, ECCV 2020–2022, WACV 2022 & 2025–2026.
Journal reviewer: JVCI, IEEE Transactions on Information Theory.
Recognition: ICML 2026 Gold Reviewer; ICLR 2025 Notable Reviewer.