My research is broadly in semi-supervised learning, active learning, multi-armed bandits, reinforcement learning, and game theory.
I am particularly interested in inverse machine learning problems known as machine teaching.
Introduction to Machine Teaching
While machine learning is about estimating a model from data, machine teaching is about passing an existing model θ to other learning agents ("students").
What makes the problem interesting is that the teacher cannot copy/paste θ to the students, just like one cannot directly hard-wire a neural network into a human student's head.
Instead, the teacher has to "talk in training data", and helps the student learn θ using their own algorithm.
For instance, here is a simple supervised-learning version of machine teaching:
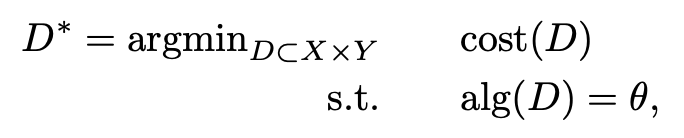
where cost() is the teacher's cost of using a training set, and alg() is the student's learning algorithm.
Note D
* does not need to be an i.i.d. sample from some underlying joint distribution p
XY.
When cost(D)=|D| the cardinality of the training set, and alg(D) returns the version space under D, machine teaching reduces to solving the teaching dimension of θ, a
fundamental learning theoretic problem.
In the other direction, machine teaching can be extended to account for a variety of teaching goals, and for more sophisticated students in sequential decision making and multi-player games.
Why should one care?
-
Machine teaching can advance education. With human students modeled by learning algorithms alg(), machine teaching finds the optimal, personalized lesson D* for them.
-
Machine teaching can make AI safer.
It helps us understand some threats facing AI agents. Just flip the intention: teacher → attacker, θ → malicious model, then D* becomes the optimal adversarial attack. The math is the same. Conversely, we can study provable defense by making alg() more resistant to attacks.
-
Machine teaching can enhance interactive machine learning.
It suggests novel approaches for domain experts to instruct a machine learner, beyond active learning.
In addition, machine teaching is intellectually fascinating.
It tends to have a combinatorial flavor since the optimization is in the data space, and requires techniques beyond standard machine learning:
- It is inverse machine learning: given a target model, find training data.
- It is control (in sequential settings): the student's estimate θt is the state at time t, alg() defines student dynamics, and Dt is the teacher's control input. The goal is to reach (near) the target state θ.
- It is communication: the teacher wants to send the model θ to the student, but the communication channel only supports messages encoded as training data, and the student decodes the message with its learning algorithm alg().
Selected Projects in Machine Teaching
Machine teaching in games
With widespread AI adoption we envision machine learning moving toward a multi-agent future, where game theoretic behaviors must be controlled. This is an opportunity for machine teaching to perform optimal mechanism design.
For instance, a teacher can convey the social-welfare-maximizing joint strategy by designing an optimal payoff matrix in which that strategy
becomes the unique Nash equilibrium.
As another example, a teacher can encourage truthful sharing of data by selfish agents using a
mechanism that adds careful corruption proportional to how much the data reported by one agent differs from the others.
Machine teaching for sequential learning agents
A typical goal here is to design the shortest training sequence to drive a sequential learner to a target state or target policy.
One may formulate this as
time-optimal control.
As a concrete application example to reinforcement learning, the teacher will identify
the shortest reward sequence to make a Q-learning agent learn a target policy.
The same principle can be applied to optimize behavior cloning.
Provable training set distillation
Our conjecture is that for most iid training sets, there is a good subset that will speed up learning. We were able to
prove this for mean estimation.
The key idea is cancellation as a subset sum problem.
For instance, let the training set be x
1 ... x
n ~ N(θ,1), and the learner estimates the sample mean θ
n. Learning on this full training set happens at a rate |θ
n-θ|=O(n
-1/2).
But for a fixed k, with large probability there exists a subset of size k that drastically speeds up the learner to rate O(n
-k).
For example, if k=2 the teacher can pick the pair x
i, x
j that is the most symmetric around θ.
We are currently extending our technique to more general learners, and approximate algorithms that find a good subset.
No learner left behind
An educator must sometimes give the same lecture to a class with diverse academic background.
Machine teaching offers an elegant solution to finding an optimal teaching set for a family of learners (e.g., they may all run logistic regression but each with a different regularization weight).
Our approach is to formulate this as
a minimax problem, where the teacher maximizes the performance of the worst learner in the class.
Teaching dimension beyond version space learners
Teaching dimension is the minimum training set size to teach a target model to a learner. Standard teaching dimension is limited to version space learners and cannot be applied to modern machine learners.
We established the teaching dimension
for ridge regression, support vector machines, and logistic regression,
as well as
for Bayesian learners in the exponential family.
Helping humans learn better
Machine teaching computes the optimal lesson for human students given an appropriate student learning algorithm.
As an example, one can digitally ``inoculate'' viewers against visual misinformation with. We use machine teaching to
select an optimal perceptual training set (representative misleading graphs and explanations) to best train human viewers for this purpose.
As another example, we construct an optimal training data set to
teach human students a categorization task. Our optimal training data set is non-iid, has interesting ``idealization'' properties, and outperforms iid training data sets sampled from the underlying test distribution.
AI safety
We study adversarial learning in multi-armed bandits, reinforcement learning, and games.
These sequential decision making victims may suffer from attacks planted over time, and via new attack surfaces such as rewards. For sequential decising making,
adversarial machine learning is a control problem.
Machine teaching offers a framework to study optimal attacks on
supervised learning,
bandits,
sequential models
reinforcement learning,
multi-agent RL, etc.
Machine teaching then allows defense through
robust statistics.
