My research focuses on machine learning.
On the algorithm side, my group invents new machine learning methods for optimal teaching, topological data analysis, semi-supervised learning, and active learning.
On the applied side, my group discovers computational models behind interesting human behaviors, and analyzes social media for social good.
My group has been supported by the
National Science Foundation,
National Institutes of Health,
AFOSR,
and
University of Wisconsin-Madison.
For a complete list of projects, data sets, and code, please visit my
publications page.
Previous Projects
What if there is a teacher who knows the learning goal (such as a target model) and wants to design the optimal (such as the smallest) training data for a learner?
This is the question of designing the best "lesson," and the inverse problem of machine learning.
Machine teaching has obvious applications in education and cognitive psychology, as well as potential applications in computer security.
The optimal training set is usually
not an
i.i.d. sample, but rather requires combinatorial search.
Finding the optimal training set is in general a difficult bilevel optimization problem, though in certain cases there are tractable solutions.
[project website]
An adversary can force machine learning to make mistakes. We study why this happens and how to defend against it.
Our research ranges from test-time attacks, training data poisoning attacks to other subtle forms of adversarial attacks.
[project website]
What is the
VC-dimension of the human mind?
Do people do
active learning? Do they do
semi-supervised learning?
Is there a mathematically optimal way to
teach them?
This project seeks a unifying theory behind machine learning and human learning.
It helps us understand how humans learn, with the potential to enhance education and produce new machine learning algorithms.
[project website]
Topology for machine learning
Persistent homology is a mathematical tool from topological data analysis.
The 0-th order homology groups correspond to clusters, while the 1st order homology groups are "holes" as in the center of a donut, and the 2nd order homology groups are "voids" as the inside of a balloon, etc. These seemingly exotic mathematical structures may provide valuable invariant data representations that complement current feature-based representations in machine learning.
Here is a gentle
tutorial for computer scientists and an idea for natural language processing.
Here is
another idea for machine learning.
Also check out the
ICML 2014 workshop on Topological Methods for Machine Learning.
Bullying is a serious national health issue. Social science study of bullying traditionally used personal surveys in schools, suffering from small sample size and low temporal resolution. We are developing novel machine learning models to study bullying. Our model aims to reconstruct a bullying event -- who the bullies, victims, witnesses are, and what happened to them -- from publicly available social media posts. Our model and data can improve the scientific study, intervention, and policy-making, of bullying.
For details see
our project website.
New: Bullying dataset for machine learning version 3.0 released in June 2015, with 7321 tweets annotated with bullying, author role, teasing, type, form, and emotion labels.
More broadly, we develop machine learning models to mine social media for social good.
For instance, our
Socioscope model help scientists estimate wildlife spatio-temporal distributions from roadkill posts (ECML-PKDD 2012 Best Paper), and
we estimate real-time air quality from Weibo posts using
another model.
To use unlabeled data or not, that is the question.
It is known that semi-supervised learning can be inferior to supervised learning if its model assumption is violated.
Can we design semi-supervised algorithms which are provably robust to such failure?
The challenge is to detect model assumption violation from limited labeled data, where semi-supervised learning is most useful.
[project website]
Incorporating logical domain knowledge into probabilistic models
Human experts are good at expressing domain knowledge as logical constraints.
Probabilistic models are good at learning from training data.
We bring the best of the two worlds together.
One example is a series of extensions to Latent Dirichlet Allocation,
ranging from
simple knowledge like "this word must be in one of these topics,"
to
ΔLDA for statistical software debugging,
to
Dirichlet forest,
to
fold.all which allows arbitrary complex domain knowledge specified in First-Order Logic and enforced via stochastic gradient descent.
This project develops algorithms that automatically generate pictures from natural language sentences so that the picture conveys the main meaning of the text.
Our approach is based on statistical machine learning and integrates semantic role labeling, image selection, and scene composition.
With professors from psychology, we have demonstrated its effectiveness in improving young student's reading comprehension and math skills.
We are collaborating with the Department of Communicative Disorders to develop an iPad app as an augmentative and alternative communication device for people with disabilities (right).
A prototype is being used by clinicians in therapy for patients with autism.
[project website]
Software provenance
Each computer program undergoes a variety of transformations: instantiation in a programming language, compilation by particular compiler with specific compilation options, and possible post-compilation transformation like link-time optimization or obfuscation or packing. Given a program binary without any symbolic information, we use machine learning techniques (CRFs) to recover its provenance -- the specific stages of the transformative process,
including
authorship,
source language, compiler and optimization levels,
and infer
function entry points.
Software provenance gives insight into how binaries were produced, with applications in software engineering and debugging, malware analysis, and digital forensics.
Text classification: wishes, metaphors, creativity
Conventional text classification was about grouping documents by topic.
There is increasing interest in classifying text along novel dimensions.
We built classifiers to
identify wishful expressions,
recognize the use of metaphors,
gauge writer creativity,
and
analyze sentiment polarity
in text documents.
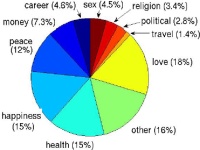
The figure on the right shows a break down of new year's wishes in 2008.