CS639 Undergraduate Elective Topics in
Computing:
Parallel and Throughput-Optimized Programming
Spring Semester 2020
Course outline
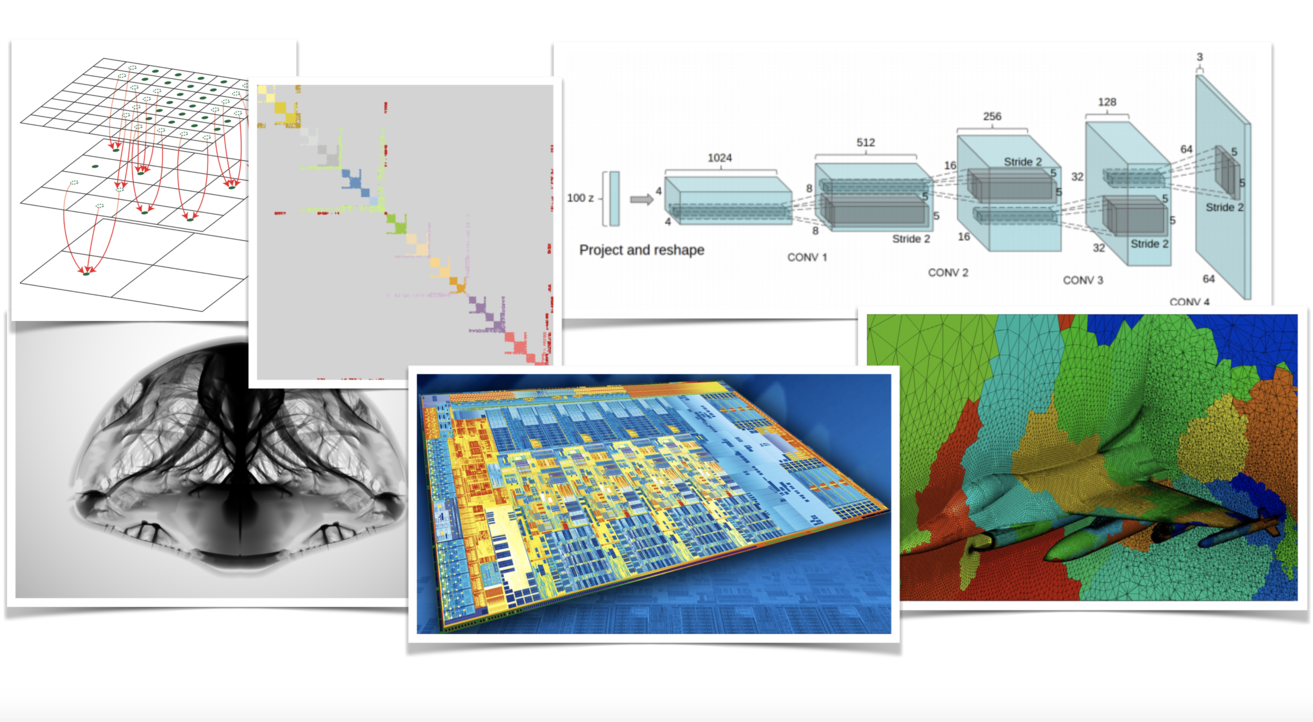
Modern computing platforms offer dramatically increased computational capabilities compared to typical systems in relatively recent generations. Today, a consumer-grade gaming desktop can rival a typical medium-scale cluster from the early 2010’s, while a well-equipped single-chassis server may pack computational power commensurate with supercomputers that would appear in the TOP500 list about 8 years ago. This dramatic increase in computational density, however, comes with significant new challenges for the platform programmer that seeks to extract optimal performance: algorithms that exploit the full potential of modern computers need to be properly designed as to be in sync with parallel programming paradigms, and be more aware than ever of the idiosyncrasies of the underlying computing architecture.
This (new and experimental) course aspires to discuss challenges as well as best practices for the design of high-performance codes, with a depth and scope tailored to be accessible to undergraduates with modest programming experience. Rather than regarding the algorithm being used as an immutable specification (and focusing on the APIs that can help engineer a parallel implementation), we shall test and often alter then algorithmic approach itself in order to create better conditions for a high-efficiency parallel implementation. At the same time, we will attempt to deepen our awareness of the intricate architectural traits of the computing platform to better understand obstacles against and opportunities for optimal efficiency.
In the first offering of this Topics course in Spring 2020, the scope will be consciously kept narrow as to allow for adequate depth and analysis of the topics covered. Specifically, we will emphasize shared-memory, single-chassis multiprocessor systems as our primary target platform (with GPUs garnering some, but limited coverage), and forego highly heterogeneous platforms or distributed systems such as network-connected multi-node clusters. Our application focus and case studies will also be drawn primarily from numerical algorithms, scientific computing and computational engineering (with higher-level applications such as image processing, computational physics or machine learning naturally emerging from those). We will not explicitly emphasize combinatorial workloads (e.g. search and hashing), algorithms that rely heavily on unstructured, random data access, or applications that do not have high-throughput processing as a central design objective.
Programming paradigms, design practices, and platform considerations to be discussed in class may include:
Topics from which case studies and sample workloads will be drawn include the following facets of scientific computing:
General information
Lecture meeting time : Tue/Thu 2:30pm -
3:45pm
Office hours : Virtually via Google Meet (look at Piazza page for details)
Lecture location : ONLINE (via video lectures) since March 24th
Instructor : Eftychios Sifakis
Office : Computer Sciences building, Room 6387
Email : sifakis <at> cs <dot> wisc <dot> edu
Prerequisites : Working knowledge of the C programming language is presumed, as well as familiarity with principles of machine organization. CS354 or equivalent is strongly recommended (can be waived with instructor consent). Familiarity with basic linear algebra is desirable, but no formal prerequisite is enforced.
Schedule of lectures
| DATE | Lecture Information | Assignments & Reading Materials |
Tuesday, January 21st |
Introduction to CS639 |
Lecture Notes [PDF] |
Thursday, January 23rd |
Discussion of different types of Concurrency |
Review Ruud van der Pas' OpenMP slides [PDF] |
Tuesday, January 28th |
Introduction to Stencil operations on Grids. Implementation and evaluation of variants of a Laplacian kernel. |
Lecture Notes [PDF] |
Thursday, January 30th |
Stencil operations on Grids (continued discussion of Laplacian kernel). Introduction to Vectorization and SIMD processing. |
Lecture Notes [PDF] |
Tuesday, February 4th |
Introduction to Vectorization and SIMD processing (cont'd). Introduction to Sparse Linear Solvers (using Stencils) |
Lecture Notes [PDF] |
Thursday, February 6th |
Matrix-Free Sparse Solvers (Laplace equation Part #1) |
Lecture Notes [PDF] |
Tuesday, February 11th |
Code Review : A Matrix-Free solver for the 3D Poisson Equation (Part I) (Factorization of code into kernels, reductions, and parallelization considerations) |
Continuation of notes from Feb 4th. Review code in our repository, at subdirectory LaplaceSolver_0_1 |
Thursday, February 13th |
Code Review : A Matrix-Free solver for the 3D Poisson Equation (Part II) (Kernel aggregation, aggregate timing). Introduction to Sparse Matrix Formats |
Continuation of notes from Feb 4th. |
Tuesday, February 18th |
Introduction to Sparse Matrices |
Lecture Notes [PDF] |
Thursday, February 20th |
Sparse matrix computations (cont'd). Use in Conjugate Gradients. Operations on the transpose. |
Lecture Notes [PDF] |
Tuesday, February 25th |
Sparse matrix computations (cont'd). Transpositions, and forward/backward substitution. |
Lecture Notes [PDF] |
Thursday, February 27th |
Sparse matrix computations (cont'd). Triangular systems. |
Lecture Notes [PDF] |
Tuesday, March 3rd |
Sparse matrix computations (cont'd). Forward/Backward substitution and Preconditioned Conjugate Gradients. Midterm review. |
Practice Midterm [PDF] |
Thursday, March 5th |
Sparse matrix computations (cont'd). BLAS and MKL. |
Lecture notes[PDF] |
Friday March 6th |
MIDTERM: 7:15pm-9:15pm CS1221 |
|
Tuesday, March 10th |
Introduction to Dense algebra. |
Lecture notes[PDF] |
Thursday, March 12th |
Introduction to Dense algebra. |
Lecture notes[PDF] |
Tuesday, March 24th |
Optimization of GEMM operations (Part#1) |
Video lectures online on
Canvas |
Tuesday, March 26th |
Optimization of GEMM operations (Part#2) |
Video lectures online on Canvas |
Tuesday, March 31st |
Optimization of GEMM operations (Part#3 - Advanced optimizations) |
Video lectures online on
Canvas |
Thursday, April 2nd |
Optimization of GEMM operations (Part#4 - Assembly-Level optimizations) |
Video lectures online on
Canvas |
Tuesday, April 7th |
Optimization of GEMM operations (Part#5 - Using assembly-language intrinsics) |
Video lectures online on
Canvas |
Thursday, April 9th |
Additional BLAS Level 3 Operations in MKL |
Video lectures online on
Canvas |
Tuesday, April 14th |
Dense direct matrix solvers in MKL/LAPACK |
Video lectures online on
Canvas |
Thursday, April 16th |
Parallel Sparse Direct solvers (intro to MKL PARDISO) |
Video lectures online on
Canvas |
Tuesday, April 21st |
Parallel Sparse Direct solvers - Parallelism and Design traits in MKL PARDISO |
Video lectures online on
Canvas |
Thursday, April 23rd |
Design and Performance of MKL PARDISO (cont'd) - Brief notes on prefetching |
Video lectures online on
Canvas |
Tuesday, April 28th |
Exam review (Part #1) |
Video commentary online on
Canvas |
Thursday, April 30th |
Exam review (Part #2) |
Video commentary online on
Canvas |