Prev: W5 Next: W7
Blank Slides (with blank pages for quiz questions): Part 1, Part 2,
Annotated Slides: Part 1, Part 2,
Part 2 (Gradient Filters): Link
Part 3 (Computer Vision): Link
Part 4 (Computer Vision): Link
Part 5 (Viola Jones): Link
Part 6 (Convolutional Neural Net): Link
Canny Edge Detection: Link
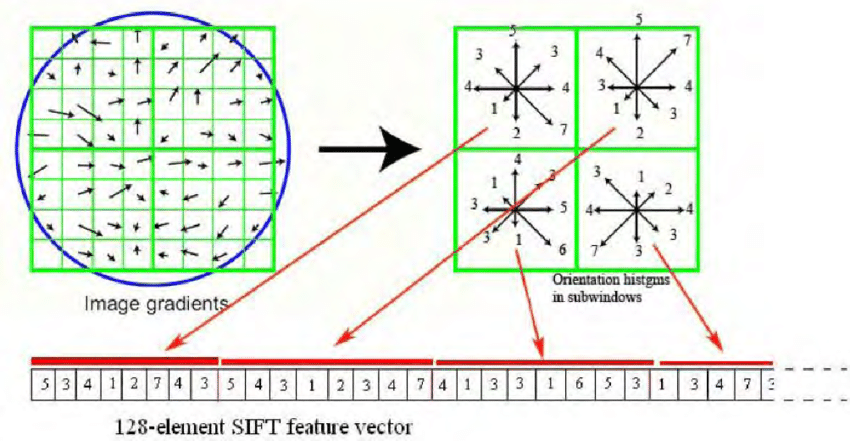
SIFT: PDF
HOG: PDF
Conv Net on MNIST: Link
Conv Net Vis: Link
LeNet: PDF, Link
Google Inception Net: PDF
CNN Architectures: Link
Image to Image: Link
Image segmentation: Link
Image colorization: Link, Link
Image Reconstruction: Link
Style Transfer: Link
Move Mirror: Link
Pose Estimation: Link
YOLO Attack: YouTube
Convolution (2D): \(A = X \star W\), \(A_{j j'} = \displaystyle\sum_{s=-k}^{k} \displaystyle\sum_{t=-k}^{k} W_{s,t} X_{j-s,j'-t}\), where \(W\) is the filter, and \(k\) is half of the width of the filter.
Sobel filter: \(W_{x} = \begin{bmatrix} -1 & 0 & 1 \\ -2 & 0 & 2 \\ -1 & 0 & 1 \end{bmatrix}\) and \(W_{y} = \begin{bmatrix} -1 & -2 & -1 \\ 0 & 0 & 0 \\ 1 & 2 & 1 \end{bmatrix}\).
Image gradient: \(\nabla_{x} X = W_{x} \star X\), \(\nabla_{y} X = W_{y} \star X\), with gradient magnitude \(G = \sqrt{\nabla_{x}^{2} + \nabla_{y}^{2}}\) and gradient direction \(\Theta = arctan\left(\dfrac{\nabla_{y}}{\nabla_{x}}\right)\).
Convolution layer: \(A = g\left(W \star X + b\right)\), where \(A\) is the activation map.
Pooling layer: (max-pooling) \(a = \displaystyle\max\left\{x_{1}, ..., x_{m}\right\}\), (average-pooling) \(a = \dfrac{1}{m} \displaystyle\sum_{j=1}^{m} x_{j}\).
# Summary
📗 Monday lecture: 5:30 to 8:30, Zoom Link
📗 Office hours: 5:30 to 8:30 Wednesdays (Dune) and Thursdays (Zoom Link)
📗 Personal meeting room: always open, Zoom Link
📗 Quiz (use your wisc ID to log in (without "@wisc.edu")): Socrative Link, Regrade request form: Google Form (select Q6).
📗 Math Homework:
M6,
📗 Programming Homework:
P3,
📗 Examples, Quizzes, Discussions:
Q6,
# Lectures
📗 Slides (before lecture, usually updated on Saturday):
Blank Slides:
Part 1,
Part 2,
Blank Slides (with blank pages for quiz questions): Part 1, Part 2,
📗 Slides (after lecture, usually updated on Tuesday):
Blank Slides with Quiz Questions:
Part 1,
Part 2,
Annotated Slides: Part 1, Part 2,
📗 My handwriting is really bad, you should copy down your notes from the lecture videos instead of using these.
📗 Notes
# Other Materials
📗 Pre-recorded Videos from 2020
Part 1 (Convolution): Link Part 2 (Gradient Filters): Link
Part 3 (Computer Vision): Link
Part 4 (Computer Vision): Link
Part 5 (Viola Jones): Link
Part 6 (Convolutional Neural Net): Link
📗 Relevant websites
Image Filter: Link Canny Edge Detection: Link
SIFT: PDF
HOG: PDF
Conv Net on MNIST: Link
Conv Net Vis: Link
LeNet: PDF, Link
Google Inception Net: PDF
CNN Architectures: Link
Image to Image: Link
Image segmentation: Link
Image colorization: Link, Link
Image Reconstruction: Link
Style Transfer: Link
Move Mirror: Link
Pose Estimation: Link
YOLO Attack: YouTube
📗 YouTube videos from 2019 to 2021
# Keywords and Notations
📗 Convolution
Convolution (1D): \(a = x \star w\), \(a_{j} = \displaystyle\sum_{t=-k}^{k} w_{t} x_{j-t}\), where \(w\) is the filter, and \(k\) is half of the width of the filter. Convolution (2D): \(A = X \star W\), \(A_{j j'} = \displaystyle\sum_{s=-k}^{k} \displaystyle\sum_{t=-k}^{k} W_{s,t} X_{j-s,j'-t}\), where \(W\) is the filter, and \(k\) is half of the width of the filter.
Sobel filter: \(W_{x} = \begin{bmatrix} -1 & 0 & 1 \\ -2 & 0 & 2 \\ -1 & 0 & 1 \end{bmatrix}\) and \(W_{y} = \begin{bmatrix} -1 & -2 & -1 \\ 0 & 0 & 0 \\ 1 & 2 & 1 \end{bmatrix}\).
Image gradient: \(\nabla_{x} X = W_{x} \star X\), \(\nabla_{y} X = W_{y} \star X\), with gradient magnitude \(G = \sqrt{\nabla_{x}^{2} + \nabla_{y}^{2}}\) and gradient direction \(\Theta = arctan\left(\dfrac{\nabla_{y}}{\nabla_{x}}\right)\).
📗 Convolutional Neural Network
Fully connected layer: \(a = g\left(w^\top x + b\right)\), where \(a\) is the activation unit, \(g\) is the activation function. Convolution layer: \(A = g\left(W \star X + b\right)\), where \(A\) is the activation map.
Pooling layer: (max-pooling) \(a = \displaystyle\max\left\{x_{1}, ..., x_{m}\right\}\), (average-pooling) \(a = \dfrac{1}{m} \displaystyle\sum_{j=1}^{m} x_{j}\).
Last Updated: June 27, 2026 at 9:06 PM